1. 概述
postgresql作为目前新型的关系型数据,其实和oracle这种老爷爷和mysql这种壮年男子比起来,市场份额并不是非常多。但是自从mysql在oracle的开源协议到期之际,天知道oracle会不会对mysql下刀,所以开源社区目前正在寻求一种新的解决方案,也就是postgresql。
postgresql也是非常稳定的一款关系型数据库,他是早期伯克利大学的postgres数据库演变而来,目前已经到了12版本。目前很多开源软件,比如:harbor,gitlab,zabbix,grafana已经开始支持pgsql或者说直接放弃了mysql而使用pgsql作为后端数据库了。我们这边的开源软件基本都是选择了pgsql作为了后端的数据库,但是我们前面做的都是单机的解决方案,但是如果要在生产中使用,仅仅使用单机是远远不够的,备份和高可用是我们首先要考虑的问题。不过我们不是讲数据库,所以我们把高可用和备份的配置方法教给大家,具体的关系型数据库知识还需要大家自己探索。
2. 高可用
关于postgresql的高可用方案真的是太多了,主要还是由于社区的活跃,wiki上列出的集群方案比较
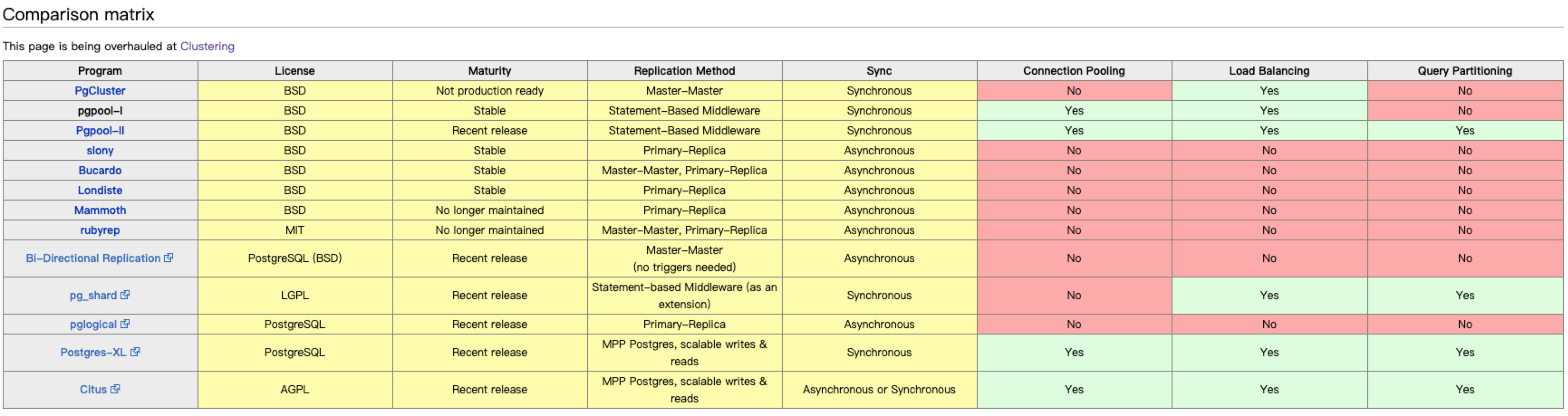
我们这里使用的是第二象限公司推出的流复制管理工具repmgr。
2.1. repmgr特点
repmgr的特点是非常轻量,单功能全面
- 他支持故障自动转移和手动切换
- 支持分布式管理集群节点,易扩展,可以在线增加或者删除节点
2.2. 命令
repmgr管理命令有repmgr和repmgrd两个命令。
-
repmgr:实现对集群节点的管理,比如注册主备节点,克隆节点,promote节点,follow节点,手动切换等
-
repmgrd:用来启动repmgr系统的守护进程
2.3. 架构图

repmgr管理工具对集群节点的管理是基于一个分布式的管理系统。每个节点都有自己的repmgr.conf配置文件,文件中会来记录本节点的ID,节点名称,连接,数据库目录等信息。
3. 配置集群
| IP地址 | 机器名 | 组件 |
|---|---|---|
| 192.168.220.11/192.168.11.129 | pgsql1 | pgsql12, repmgr, keepalived |
| 192.168.220.12/192.168.11.136 | pgsql2 | pgsql12, repmgr, keepalived |
3.1. 安装单机版
-
在主节点192.168.220.11上启动一个单机的postgresql,下载地址
-
安装yum源
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm -
安装版本12
yum install -y postgresql12-server -
刚开始安装完成时候是没有任何数据的,我们需要修改一些参数
/usr/lib/systemd/system/postgresql-12.service,比如指定数据目录Environment=PGDATA=/data/pgsql -
修改数据目录的权限
mkdir -p /data/{pgsql,archive,backup} chown -R postgres:postgres /data/pgsql/ chown -R postgres:postgres /data/archive/ chown -R postgres:postgres /data/backup/ -
然后初始化,相关的数据文件就会出现在/data/pgsql/下面了
/usr/pgsql-12/bin/postgresql-12-setup initdb -
开机启动
systemctl enable postgresql-12
3.2. 准备工作
-
在standby节点上重复3.1的工作,但是不要启动
-
配置postgresql用户的ssh互信
- primary节点
[root@pgsql2 pgsql]# passwd postgres 更改用户 postgres 的密码 。 新的 密码: 无效的密码: 密码包含用户名在某些地方 重新输入新的 密码: passwd:所有的身份验证令牌已经成功更新。 [root@pgsql1 pgsql]# su - postgres 上一次登录:一 9月 21 20:36:10 CST 2020pts/0 上 -bash-4.2$ ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa Generating public/private rsa key pair. Created directory '/var/lib/pgsql/.ssh'. Your identification has been saved in /var/lib/pgsql/.ssh/id_rsa. Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub. The key fingerprint is: SHA256:TJWBvBfoRbhCLmwjjyM07hifKAehNNT+p3BWHiypBzI postgres@pgsql1 The key's randomart image is: +---[RSA 2048]----+ | . . =+o | | . . . =.+ | |. .. oo..+ . | |.E.o=oo*+ . | |=.==+o+.S. | |=.oo.= o | |o* o= o | |+.+ . | |.. | +----[SHA256]-----+- standby节点
[root@pgsql2 pgsql]# passwd postgres 更改用户 postgres 的密码 。 新的 密码: 无效的密码: 密码包含用户名在某些地方 重新输入新的 密码: passwd:所有的身份验证令牌已经成功更新。 [root@pgsql2 pgsql]# su - postgres 上一次登录:一 9月 21 20:48:00 CST 2020pts/0 上 -bash-4.2$ ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa Generating public/private rsa key pair. Created directory '/var/lib/pgsql/.ssh'. Your identification has been saved in /var/lib/pgsql/.ssh/id_rsa. Your public key has been saved in /var/lib/pgsql/.ssh/id_rsa.pub. The key fingerprint is: SHA256:xB86WrFnCTfS6sjp374O/3GAwQhjZPRrOF4KYiKJvzo postgres@pgsql2 The key's randomart image is: +---[RSA 2048]----+ | oB | | o = + | | O B | |.. o @ * | |= o . o S * . | |.+ . + @ + . | | . B o . . | |E . . + o | |.o. ...o*o. | +----[SHA256]-----+ -bash-4.2$ ssh-copy-id 192.168.220.11 /bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/var/lib/pgsql/.ssh/id_rsa.pub" /bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys postgres@192.168.220.11's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh '192.168.220.11'" and check to make sure that only the key(s) you wanted were added.- 回到主节点
-bash-4.2$ ssh-copy-id 192.168.220.12 /bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/var/lib/pgsql/.ssh/id_rsa.pub" /bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys postgres@192.168.220.12's password: Permission denied, please try again. postgres@192.168.220.12's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh '192.168.220.12'" and check to make sure that only the key(s) you wanted were added. -
在主节点上配置
/data/pgsql/postgresql.conf的必要参数listen_addresses = '0.0.0.0' max_wal_senders = 10 max_replication_slots = 10 wal_level = replica hot_standby = on archive_mode = on archive_command = 'test ! -f /data/archive/%f && cp %p /data/archive/%f' -
启动数据库
systemctl start postgresql-12 -
切换到postgres用户并启动数据库
# su - postgres -c "psql" psql (12.4) Type "help" for help. postgres=# -
创建repmgr用户 ,以及创建repmgr 数据库
postgres=# create database repmgr; CREATE DATABASE postgres=# create user repmgr with password 'repmgr' superuser login; CREATE ROLE postgres=# alter database repmgr owner to repmgr; ALTER DATABASE -
配置/data/pgsql/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust # IPv4 local connections: host all all 127.0.0.1/32 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 192.168.220.0/24 trust host all all 0.0.0.0/0 md5 # IPv6 local connections: host all all ::1/128 trust # Allow replication connections from localhost, by a user with the # replication privilege. local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 192.168.220.0/24 trust
3.3. 主节点安装repmgr
-
下载地址:https://repmgr.org/,官方手册:https://repmgr.org/docs/current/installation-packages.html,可以选择编译的方式,但是建议选择rpm方式
curl https://dl.2ndquadrant.com/default/release/get/12/rpm | bash yum install -y repmgr12 -
配置环境变量
cat << EOF >/etc/profile.d/pgsql.sh export PATH=/usr/pgsql-12/bin:$PATH EOF source /etc/profile -
修改/etc/repmgr/12/repmgr.conf
node_id=1 node_name='192.168.220.11' conninfo='host=192.168.220.11 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/data/pgsql' -
启动
su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf primary register" INFO: connecting to primary database... NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed NOTICE: primary node record (ID: 1) registered -
查看
[root@pgsql1 pgsql]# su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show" ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string ----+----------------+---------+-----------+----------+----------+----------+----------+----------------------------------------------------------------- 1 | 192.168.220.11 | primary | * running | | default | 100 | 1 | host=192.168.220.11 user=repmgr dbname=repmgr connect_timeout=2
3.4. 在第二个节点上
-
配置
/data/pgsql/postgresql.conf的必要参数listen_addresses = '0.0.0.0' max_wal_senders = 10 max_replication_slots = 10 wal_level = replica hot_standby = on archive_mode = on archive_command = 'test ! -f /data/archive/%f && cp %p /data/archive/%f' -
安装repmgr
curl https://dl.2ndquadrant.com/default/release/get/12/rpm | bash yum install -y repmgr12 -
修改/etc/repmgr/12/repmgr.conf
node_id=2 node_name='192.168.220.12' conninfo='host=192.168.220.12 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/data/pgsql' -
测试
# su - postgres -c "/usr/pgsql-12/bin/repmgr -h 192.168.220.11 -U repmgr -d repmgr -f /etc/repmgr/12/repmgr.conf standby clone --dry-run" NOTICE: destination directory "/data/pgsql" provided INFO: connecting to source node DETAIL: connection string is: host=192.168.220.11 user=repmgr dbname=repmgr DETAIL: current installation size is 32 MB INFO: "repmgr" extension is installed in database "repmgr" INFO: parameter "max_wal_senders" set to 10 NOTICE: checking for available walsenders on the source node (2 required) INFO: sufficient walsenders available on the source node DETAIL: 2 required, 10 available NOTICE: checking replication connections can be made to the source server (2 required) INFO: required number of replication connections could be made to the source server DETAIL: 2 replication connections required WARNING: data checksums are not enabled and "wal_log_hints" is "off" DETAIL: pg_rewind requires "wal_log_hints" to be enabled NOTICE: standby will attach to upstream node 1 HINT: consider using the -c/--fast-checkpoint option INFO: all prerequisites for "standby clone" are met -
clone主节点数据
# su - postgres -c "/usr/pgsql-12/bin/repmgr -h 192.168.220.11 -U repmgr -d repmgr -f /etc/repmgr/12/repmgr.conf standby clone" NOTICE: destination directory "/data/pgsql" provided INFO: connecting to source node DETAIL: connection string is: host=192.168.220.11 user=repmgr dbname=repmgr DETAIL: current installation size is 32 MB NOTICE: checking for available walsenders on the source node (2 required) NOTICE: checking replication connections can be made to the source server (2 required) WARNING: data checksums are not enabled and "wal_log_hints" is "off" DETAIL: pg_rewind requires "wal_log_hints" to be enabled INFO: checking and correcting permissions on existing directory "/data/pgsql" NOTICE: starting backup (using pg_basebackup)... HINT: this may take some time; consider using the -c/--fast-checkpoint option INFO: executing: /usr/pgsql-12/pg_basebackup -l "repmgr base backup" -D /data/pgsql -h 192.168.220.11 -p 5432 -U repmgr -X stream sh: /usr/pgsql-12/pg_basebackup: No such file or directory ERROR: unable to take a base backup of the primary server HINT: data directory ("/data/pgsql") may need to be cleaned up manually -
查看传输的状态
select * from pg_stat_wal_receiver; -
启动standby节点
systemctl start postgresql-12 -
注册节点
su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf standby register" -
查看状态
[root@pgsql1 pgsql]# su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show" WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string ----+----------------+---------+-----------+----------------+----------+----------+----------+----------------------------------------------------------------- 1 | 192.168.220.11 | primary | * running | | default | 100 | 1 | host=192.168.220.11 user=repmgr dbname=repmgr connect_timeout=2 2 | 192.168.220.12 | standby | running | 192.168.220.11 | default | 100 | 1 | host=192.168.220.12 user=repmgr dbname=repmgr connect_timeout=2
3.4. 主备切换
-
切换主备,需要在备库上执行
su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf standby switchover -U repmgr --verbose" NOTICE: using provided configuration file "/etc/repmgr/12/repmgr.conf" WARNING: following problems with command line parameters detected: database connection parameters not required when executing STANDBY SWITCHOVER NOTICE: executing switchover on node "192.168.220.12" (ID: 2) INFO: searching for primary node INFO: checking if node 1 is primary INFO: current primary node is 1 INFO: SSH connection to host "192.168.220.11" succeeded WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less INFO: 10 pending archive files INFO: replication lag on this standby is 0 seconds NOTICE: local node "192.168.220.12" (ID: 2) will be promoted to primary; current primary "192.168.220.11" (ID: 1) will be demoted to standby NOTICE: stopping current primary node "192.168.220.11" (ID: 1) WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less NOTICE: issuing CHECKPOINT on node "192.168.220.11" (ID: 1) DETAIL: executing server command "/usr/pgsql-12/bin/pg_ctl -D '/data/pgsql' -W -m fast stop" INFO: checking for primary shutdown; 1 of 60 attempts ("shutdown_check_timeout") INFO: checking for primary shutdown; 2 of 60 attempts ("shutdown_check_timeout") INFO: checking for primary shutdown; 3 of 60 attempts ("shutdown_check_timeout") INFO: checking for primary shutdown; 4 of 60 attempts ("shutdown_check_timeout") INFO: checking for primary shutdown; 5 of 60 attempts ("shutdown_check_timeout") WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less NOTICE: current primary has been cleanly shut down at location 0/B000028 NOTICE: promoting standby to primary DETAIL: promoting server "192.168.220.12" (ID: 2) using pg_promote() NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete INFO: standby promoted to primary after 1 second(s) NOTICE: STANDBY PROMOTE successful DETAIL: server "192.168.220.12" (ID: 2) was successfully promoted to primary WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less INFO: local node 1 can attach to rejoin target node 2 DETAIL: local node's recovery point: 0/B000028; rejoin target node's fork point: 0/B0000A0 NOTICE: setting node 1's upstream to node 2 WARNING: password file "/var/lib/pgsql/.pgpass" has group or world access; permissions should be u=rw (0600) or less WARNING: unable to ping "host=192.168.220.11 user=repmgr dbname=repmgr connect_timeout=2" DETAIL: PQping() returned "PQPING_NO_RESPONSE" NOTICE: starting server using "/usr/pgsql-12/bin/pg_ctl -w -D '/data/pgsql' start" NOTICE: NODE REJOIN successful DETAIL: node 1 is now attached to node 2 INFO: node "192.168.220.11" (ID: 1) is pingable INFO: node "192.168.220.11" (ID: 1) has attached to its upstream node NOTICE: node "192.168.220.12" (ID: 2) promoted to primary, node "192.168.220.11" (ID: 1) demoted to standby NOTICE: switchover was successful DETAIL: node "192.168.220.12" is now primary and node "192.168.220.11" is attached as standby NOTICE: STANDBY SWITCHOVER has completed successfully -
查看
[root@pgsql2 pgsql]# su - postgres -c "/usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show" ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string ----+----------------+---------+-----------+----------------+----------+----------+----------+----------------------------------------------------------------- 1 | 192.168.220.11 | standby | running | 192.168.220.12 | default | 100 | 1 | host=192.168.220.11 user=repmgr dbname=repmgr connect_timeout=2 2 | 192.168.220.12 | primary | * running | | default | 100 | 2 | host=192.168.220.12 user=repmgr dbname=repmgr connect_timeout=2 -
切换的过程
-
根据执行地的repmgr 数据库中的记录,开始找到那个是当前的主节点,因为你是在从库执行的
-
发现主节点,并且找到其node ID
-
步连接到主节点通过SSH 协议
-
检测当前的archive 文件
-
检测主从之间的数据差距,通过wallog 来判断
-
检测没有问题,关闭主节点,如果还有没有checkpoint的,就等待checkpoint
-
开始执行 -m fast sotp 命令,快速关闭pg 主库
-
开始等待关闭,时间为1分钟,每秒侦测一次到底关没有关 (可以调节)
-
开始对从库 promote 执行promote 命令
-
开始检查从库是否promote 成功 时间1 分钟
-
将原来的主库重新加入,对比两个节点之间的日志差距
-
原主节点变更为从节点
-
3.5. 失败重做
-
关闭原主库(用任何方法都可以),如果运维自动化,可以写脚本,KILL
-
打开主库,然后使用命令将其驱逐出 repmgr 集群
repmgr standby unregister -f /etc/repmgr.conf -
关闭分离的从库
-
清理数据目录
-
重新注册
repmgr -h 192.168.220.11 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone -
更改 postgresql.conf listen 地址
-
启动从库
-
重新注册从库
repmgr -f /etc/repmgr.conf standby register
4. 配置自动切换
前面的手动切换是为了测试数据库是否可以来回的切换,在实际生产中为了保持业务的连续性,我们需要在出问题的时候实现自动切换,这个时候就有了另外一个组件来帮忙,也就是repmgrd
4.1. repmgrd
repmgrd是一个管理和监视守护进程,它在复制集群中的每个节点上运行。它可以自动执行一些操作,比如故障转移和更新备用服务器,并提供关于每个备用服务器状态的监视信息。
在使用repmgrd 的情况下,需要将其与postgresql进行绑定,也就是需要在shared_preload_libraries = 'repmgr' 中进行配置,需要加载到共享库。
在使用repmgrd 进行主从切换的有几个需要注意的地方:
-
在主从切换的过程中,等待多长时间来判断主库已经无法启动了或不是因为网络原因造成的问题,或及时是网络造成的问题,多长时间能容忍,不切换。
-
切换的过程如果不成功怎么办,什么可能的因素会导致切换失败
-
多节点,如果切换,其他的节点是否可以连接到新的主上,并继续工作
-
跨数据中心的怎么来进行高可用的规划。
4.2. 配置自动切换需要考虑的问题
- 主失败后等待切换时间,主要是两个参数重新连接主库的次数
reconnect_attempts和 时间间隔reconnect_interval,如果你的网络不稳定,或者跨机房,你自己就的适当的调整参数,已适应你出现问题后的情况。 - 切换不成功的大概率可能性是从库在从事其他的工作,而不是standby,所以这你就需要衡量一下,到底你的这个standby 的重要性是什么,是要协同工作,读写分离,还是就是一个standby 随时待命来进行切换。当你有多个standby 的时候,你还可以调整你从库的 priority
- 例如你有三个postgresql 的节点其中一主两从,当其中主节点失效后其中一个变为主节点,但另一个从节点也需要继续工作,需要链接到新的主上,这个工作在POSTGRESQL 怎么做,因为是物理复制,不是逻辑复制,所以也没有那么简单。
- 跨数据中心的postgresql 则需要考虑的问题是跨数据中心的网络问题,以及脑裂问题,例如部署一定是单数节点,那单数节点的情况下,那边的节点数量要多,而多的那边放置的是什么节点,例如我就两台postgresql 主从,跨数据中心,但我怎么能防止脑裂,则就需要引入 wintness 服务器,也就是postgresql 见证服务器,他一般放置在数据中心的 主库位置,本身不参与数据的复制和分发,如果主变得不可用备用可以决定是否它能促进本身也不用担心“分裂的场景,如果它不能看到证人或主服务器,很可能有一个网络级中断,它不应该促进本身。如果它可以看到见证而不是主节点,这证明不存在网络中断,主节点本身不可用。
4.3. 配置自动切换
修改/etc/repmgr/12/repmgr.conf文件
# 配置log,这个配置默认只给repmgr使用
log_level='INFO'
log_facility='STDERR'
log_file='/var/log/repmgr/repmgr.log'
log_status_interval=300
# repmgrd配置
failover='automatic'
connection_check_type=ping
promote_command='repmgr -f /etc/repmgr/12/repmgr.conf standby promote --log-to-file'
follow_command='repmgr -f /etc/repmgr/12/repmgr.conf standby follow --log-to-file --upstream-node-id=%n'