1. 传统虚拟化
1.1. 传统虚拟化类型
我们虚拟化的是整个硬件平台,比如:vmware系列,他让我们拿到虚拟机的时候就好像拿到了一个物理机一样。可以在上面自由的安装和使用操作系统,而安装的操作系统可以和我们的宿主机是不同的操作系统。

他有两种类型的实现
-
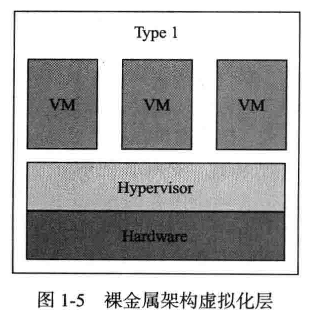
类型一:直接在硬件上安装虚拟化管理器,我们一般称他为hypervisor,也就是说不用在宿主机上安装操作系统,而直接使用hypervisor,然后在hypervisor上安装虚拟机,所有的操作系统没有跑在硬件之上,都是跑在虚拟机内部。
-
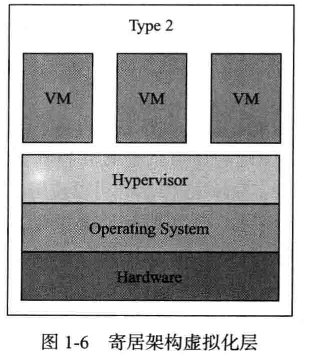
类型二:vmware workstation、virtualbox这种的。首先我们需要在物理机上安装一个操作系统,叫做hostOS,叫宿主机操作系统,在宿主机上安装vmm(virtual machine manager),在这个软件之上在创建虚拟机。
- 如果细分类,还有更多的类型,比如kvm和xen这类的软件
1.2. 从平台虚拟化到容器
而这些虚拟化技术的实现机制是:首先要有底层硬件平台,然后不管是hypervisor还是vmm,他虚拟出来的都是独立的硬件平台,所以说我们要使用这个硬件平台的话,就需要自己部署一个完整的操作系统。也就是说,我们要在虚拟机上安装一个内核,内核上又有用户空间,空间里面跑进程。而内核的作用在于资源分配和核心管理,真正能够提供生产力的是跑在用户空间内的应用程序。比如我们的web服务,nginx,httpd都是跑在用户空间的,这些都是能够提供生产力的,而不是提供资源的硬件平台与内核。但是内核又不得不存在,因为我们要想在这一系列的平台上使用软件程序,必须要使用内核所提供的系统调用和库调用。而且,我们为了运行程序,就要跑很多的进程,这些进程的隔离也必须要由内核来完成。其实我们很多时候,使用操作系统的目的就是为了运行一个单一的服务,比如tomcat,django,为此,我们却不得不安装内核安装用户空间,然后再去跑一个tomcat,这样的话代价是不是有一点大呢?
答案是肯定的,我们用我们的类型二的虚拟化来说,他需要两级调度和资源分派,宿主机的内核已经可以管理硬件了,而虚拟机上的内核又是在宿主机的内核管理之下的,抽象出来的抽象层而已。这个虚拟化出来的内核想要调度和管理硬件,就需要向宿主机发起请求,请求被宿主机的内核再调度一次才能完成。这当中的资源开销真是的太大了。
1.3. 为什么要使用容器化
这种传统的主机虚拟化技术的确能够让我们在一组硬件平台上实现跨系统环境的隔离,实验,调试或者资源的高效应用,但是他带给我们的资源开销也是不容忽视的。而往往我们创建虚拟机的时候也就是为了运行那么一两个有效的,具有生产责任的进程而已,为此,付出的代价稍微有点点大了。那么,有效的减少中间层,就是提高效率的最好的途径了。如果,我们把我们虚拟机上的内核抽掉,只保留进程,但是,我们原来需要创建虚拟机的目的之一,隔离就没法实现了。比如:我们运行两个tomcat程序,两个程序都监听80端口,而我们又只有一个IP地址,如果没有内核,隔离就没法实现。为了让进程互相隔离,即使损坏了也只影响自己,不会对其他进程产生影响。那么,我们可以这样设计,首先有一个硬件平台,在这个硬件平台上有一个虚拟的隔离管理器,而后,我们创建一个又一个的隔离环境,让我们需要运行的进程就跑在这个隔离的环境内。内核应该在内核空间,进程应该在用户空间,而我们要提供隔离环境,那么我们实际上做的是隔离用户空间。按照道理来说,我们的用户空间只有一组,但是为了实现隔离,我们就需要有多个空户空间,而一般来说,都会有一个用户空间是有特权的,我们通过他来管理其他的用户空间。随后,我们启动和运行程序的时候,把他启动在用户空间内,而众多用户空间都是通用一个底层的内核所管理。但是每个程序在运行的时候,可以看到的边界是自己所属的用户空间的边界,从而实现了隔离。但是,我们发现,这种隔离,显然没有机器隔离的彻底。我们说,这个用户空间是用来放进程的,他可以让进程运行,并且保护进程不受其他进程的干扰,那么这个就是我们的容器了。
如果说主机时代比拼的是单个服务器物理性能(如CPU主频和内存)的强弱,那么在云时代,最为看重的则是凭借虚拟化技术所构建的集群处理能力。
伴随着信息技术的飞速发展,虚拟化的概念早已经广泛应用到各种关键场景中。从20世纪60年代IBM推出的大型主机虚拟化,到后来以Xen、KVM为代表的虚拟机虚拟化,再到现在的容器技术,虚拟化技术自身也在不断进行创新和突破。
传统来看,虚拟化既可以通过硬件模拟来实现,也可以通过操作系统软件来实现。而容器技术则更为优雅,它充分利用了操作系统本身已有的机制和特性,可以实现远超传统虚拟机的轻量级虚拟化。因此,有人甚至把它称为“新一代的虚拟化”技术,并将基于容器打造的云平台亲切地称为“容器云”。
2. 容器实现的基础
2.1. namespaces
容器技术最早出现是在freeBSD上,当时叫做jail,他当时的目的就是为了运行进程,而不受到其他的干扰。像监狱一样,他提供了一个类似sandbox一样的环境,即使程序自己出现BUG或者故障等异常行为,也不至于影响其他进程这样一个出于安全目的的初衷而设计的。后来就有人把这个思想复制到了Linux平台上,到了Linux平台上,这个技术就叫做vserver,这个vserver在一定程度上也能实现jail的效果,其实vserver当时主要的应用叫做chroot,就是‘切根’,实际上真正的root只有一个。我们在做FHS实现的时候,我们创建一个符合FHS的目录结构,然后使用chroot命令把那个目录就可以当做一个操作系统来使用了。不过这并不能实现用户空间的彻底隔离,因为chroot隔离的仅仅是你看到的空间,但是想要真正的隔离,至少需要在一个单独的用户空间中。
为了实现真正的隔离,我们需要以下几个部分分别独立
-
主机名和域名:UTS,每个机器都应该有自己独立的名字。
-
根文件系统:Mount,类似chroot,让操作系统以某一个目录作为根文件系统。
-
IPC(进程间通讯的专用通道),在底层内核上,实际上是希望进程之间可以使用IPC互相通讯的,但是为了实现独立性,就必须把他们隔离开来。
-
PID,在每一个用户空间中,每一个进程应该会从属于某一个进程,因为进程都应该是有一个父进程来创建,如果他没有父进程,那他们就应该属于init。一个系统运行无非就是两棵树,进程树和文件系统树,对于这个单独的用户空间来说,既然他是唯一的,我们就要给他一个假象,如果init结束了,就要把他产生的子进程都结束掉。
-
User,我们运行的每一个进程,都应该有一个用户来运行他。我们假设,两个独立的空间中,有两个用户,虽然他们的名字不一样,但是他们的ID是一样的。比如root账户,每个空间都应该有一个ID号为0的用户,就是root,但是一个内核上只应该有一个root,我们就需要在用户空间伪装出一个root,这个root在真正的系统上应该是一个普通的用户,但是对于用户空间来说,我们可以让他ID为0,只能在用户空间内有特权。就好像我们修改某个目录的权限为特定用户,那么这个用户对于这个目录的权限是最大的。
-
Network,每个用户空间都应该有自己的IP地址,都应该有自己的端口(0-65535),也就是都应该有自己的网卡,或者是自己的TCP/IP协议栈。而容器之间有可能还需要通讯,所以就需要一个独立的网络空间。
然后,内核在形成独立的空间的时候,每一个隔离的空间,我们叫他名称空间namespace,在内核当中,我们可以创建出多个名称空间来, 来获得独立的名称空间, 让他们独立出来,而不互相干扰。目前,上述这六个已经可以通过内核原生支持,通过系统调用,向外输出,这就是namespace。比如,创建进程clone(),创建进程之后,把他放到某个名称空间,使用setns()。到目前为止,整个容器领域就是靠内核的namespaces,和chroot来实现的。下面是名称空间技术出现的对应时间
| namespace | 系统调用参数 | 隔离内容 | 内核版本 |
|---|---|---|---|
| UTS | CLONE_NEWUTS | 主机名和域名 | 2.6.19 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 | 2.6.19 |
| PID | CLONE_NEWPIC | 进程编号 | 2.6.24 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 | 2.6.29 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) | 2.4.19 |
| User | CLONE_NEWUSER | 用户和用户组 | 3.8 |
所以要想很好的使用容器技术,就必须要求我们的内核在3.8以后才行,如果大家使用的是CentOS,那么CentOS6就直接被排除了,因为他使用的是2.6的内核。
2.2. cgroup
我们知道,我们在实现主机级虚拟化的时候,创建虚拟机,需要指定CPU,内存。在使用容器虚拟化的时候,如果资源不加以限制,很容易导致其他的名称空间也受影响。其实CPU还好一点,CPU属于可压缩资源,如果得不到CPU资源,就在后面排队就好了,但是内存就不行了,如果一个进程把所有的内存都占用了,这个时候,有一个进程向内核申请内存的时候发现资源已经没有了,就会触发OOM。所以内核级别还必须实现另外一种功能,限制每一个空间中可用资源的总量。比如:我们可以让CPU来分配,我们指定在某三个用户空间中的CPU比例是1:2:1,这样分配会很有弹性。这种好处是在于,如果没有资源争抢,只有一个空间的时候,他可以使用所有资源,如果三个空间都启动,那么他们只能按照比例来分配。如果再增加一个空间,那么他就变成了1:2:1:1。还有一种方式,我们可以限制一个用户空间中的进程最多只能使用特定个数的个核。也就是说,我们可以在所有资源上做比例型分配,也可以在单一空间中实现核心绑定,只能使用几个核,在使用核心的时候不可以超过指定的数量。内存也是同样的逻辑,不同的是,如果一个空间已经占满了内存,再有新的进程启动的时候,如果没有足够内存,那么就会触发oom。这种功能需要在内核上,针对每一个名称空间来实现,而这个功能在内核级别使用的机制就叫做cgroup
我们上面说的,可以总结成下面几个概念
- 任务(task)。在cgroups中,任务就是系统的一个进程。
- 控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。
- 层级(hierarchy)。控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
- 子系统(subsystem)。一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
cgroup全称叫做Control Groups,它的功能就是把系统资源分成多个组,把每一个组内的资源,分配到用户空间的进程上去。而cgroup子系统有下面几种,这个是redhat上的
- blkio:块设备IO
- cpu:CPU
- cpuacct:CPU资源使用报告
- cpuset:多处理器平台上的CPU集合
- devices:设备访问
- freezer:挂起或恢复任务
- memory:内存用量及报告
- perf_event:对cgroup中的任务进行统一性能测试
- net_cls:cgroup中的任务创建的数据报文的类别标识符
这就好比,大家都是在一个锅里吃饭的孩子,有些孩子属于根正苗红,有些孩子属于黑五类,有些属于贫下中农,臭老九属于一组,对这些组,我们可以会根据不同的配额来分配粮票,有的组会分到90份,有的组会分到1份。我们可以实现对一个系统上所要运行的进程给分类,每一类就是一个组,叫控制组。而后把有限的资源进行指派。然后在组内还可以再次划分,比如:成年黑五类和黑崽子们。一旦我们把一个资源分配给某一个组之后,这个组内的子组可以自动的使用这个资源,除非我们单独对他做分配,否则他就拥有这个资源所有的使用权限。
3. 容器
3.1. LXC
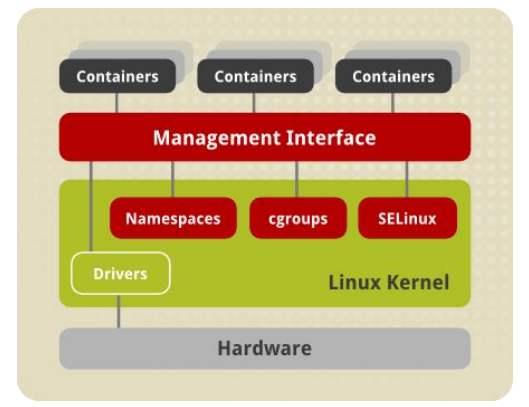
有了namespaces和cgroups,我们终于可以愉快的使用容器了。但是实际上容器的隔离能力对于主机级别的隔离还是差很多,大家毕竟是属于同一个内核,他只不过是在内核级别强行设置的边界,而不像主机虚拟化,大家本来就不属于同一个内核,内核本身就是天然隔离的平台。到今天为止,这个问题依然存在,为了加强安全性,为了避免一个用户空间中的进程绕过边界去影响其他的空间,大家就通过selinux等各种安全机制来加强空间的边界。所以为了支撑我们的容器技术做的更加完善,我们可能还需要启动selinux等一些额外的机制。我们用的容器技术基本上就是chroot,namespaces和cgroups。

而为了实现容器技术,我们就需要通过编程的方式,使用系统调用来实现容器。这个对于我们普通用户来说,基本是不太可能实现的。所以我们最好把能够实现容器的功能做成一组工具,这样能够极大的降低用户使用容器的复杂度,于是,就有了这个解决方案叫LXC(LinuX Countainer)。他是除了vserver以外,最早的容器技术,通过一组简易使用的工具和模板来极大的简化了容器使用的一个方案,所以叫做LXC。
比如lxc-create,可以快速创建一个容器。但是,我们如果想在centos的机器上创建一个ubuntu的机器,而且需要在ubuntu的机器上安装各种命令,这就需要通过一个脚本来创建,这个脚本就叫模板template,在创建名称空间之后,会执行这个template来安装,而这个安装只去安装你指定安装的操作系统所必须的软件,最后通过chroot把他作为空间的根文件系统。这样,每个空间就像一个独立的虚拟机一样使用,里面有各种需要的文件和用户账号,里面还可以额外安装其他的应用程序,启动服务,监听端口,都可以。
但是,这个依然很不方便,想要使用LXC就必须要使用各种LXC的工具,我们还要去定制模板,更重要的是,用户空间都是安装生成的,我们后来在里面运行过程当中生成了很多文件,或者数据,那么这些数据将来在出现故障以后,我们想要迁移到其他的宿主机上去就非常的困难。还有,如果我们想要大量的创建这样的容器,也是非常困难的。所以从这个角度来讲,LXC虽然极大的简化了用户的使用,但是比起来我们在使用虚拟机的时候,很大程度上没有降低难度,而且他的隔离性又没有虚拟机好,他最大的优势就在于,他能够让每一个用户空间中的进程能够使用宿主机的性能,中间没有额外开销,实现了资源上的节约。除此之外,在分发上,大规模使用上,依然没有找到很好的突破口,于是,后来就出现了Docker,从这个角度来说,他就是LXC的增强版,自己并不是容器,只是容器技术的前端工具,而容器,是内核的技术,他只是把这种技术简化,然后普及了而已。

那么Docker,就把我们刚才说的,从大规模部署,工具的易用性方面着手,做解决方案。Docker早期的版本,核心就是LXC。可以认为Docker就是lxc的封装发行版,他利用LXC做容器管理引擎,但是在创建用户空间不是LXC的传统的方式来部署容器,而是通过镜像技术。就好像kvm当中的镜像,我们把整个系统打包成为一个镜像,我们想要启动虚拟机的时候,只需要把镜像拷贝过去,创建虚拟机。我们可以把一个操作系统的用户空间上所用到的所有组件,事先编排好,把他整体打包成一个文件。这个文件就叫做镜像文件,这个镜像文件是放在一个集中统一的仓库当中的,比如一个互联网上大家都能访问到的位置,我把一个纯净的最小化的操作系统打包成镜像,放在仓库内,有很多用户可能会有跑应用的需求,比如,我要跑一个nginx。我就要把centos装好nginx再打包成一个镜像,也放在这个仓库当中,如果我们想启动容器,Docker在创建容器的时候,不会运行LXC的模板,而是连到镜像服务器上,找到匹配到你要的操作系统或者应用程序的镜像。把镜像拖到本地,基于镜像启动容器。所以说,docker极大的降低了容器的使用难度,以后,我们想启动容器,就直接docker run。他自动会链接到仓库去下载,这些在仓库里面都可以找到。为了使得整个容器更加易于管理,docker还采用了另外一种方式。我们刚才说到,在一个用户空间当中,我们可以运行一组进程。而docker采用了更精巧的方式,一个容器内只运行一个进程,比如,我们需要nginx和tomcat,那么nginx有nginx容器,tomcat有tomcat容器,二者通过容器间通讯来进行通讯。所以一个容器只运行一个进程。而lxc把一个容器当做一个用户空间使用,里面会运行很多进程。这让我们的管理变得极为不便,而docker用这种限制的方式,在一个容器中只运行一个进程。这样的设计,使得整个容器的环境都是为了运行某一个进程而存在的,而我们运行这个程序,需要什么资源就给他什么资源,需要/var/log就给/var/log目录,需要ssl的库,就安装ssl的库,不需要的一律不安装。这样一来,原来共享的文件就需要存多份,为每个需要的空间都存一份,虽然原来共享的资源需要分出多份,这样的好处就在于如果一个空间的库被删了,不会影响其他的空间。还有一个坏处,比如,我们想定位问题,我们可能会使用一些比如ps,top命令,这些调试工具也需要准备多份,这样就消耗了更多的空间,所以一般来说这些辅助的进程一般不会启动,只有需要时候才启动。有的镜像甚至不提供调试工具,这样就让我们的调试变得复杂,而且调试的时候还需要进入到名称空间内部,所以容器技术给运维带来了很多的不便,但是他给我们的开发带来了极大的便利之处。分发非常容易,一次编写,到处运行。 只要在机器上安装Docker,一个命令就可以搞定。同时也让部署更加容易,不需要考虑环境的复杂性。比如,我们原来发布,需要打包到仓库,然后运维从仓库拉取包,创建目录,解压,还要停应用,在启动。而现在只需要一个镜像,还需要一个容器编排工具,就可以搞定,容器编排工具负责把镜像分发到指定的机器上运行。
3.2. Docker开源项目
Docker是基于Go语言实现的开源容器项目。它诞生于2013年年初,最初发起者是dotCloud公司。Docker自开源后受到业界广泛的关注和参与,目前已有80多个相关开源组件项目(包括Containerd、Moby、Swarm等),逐渐形成了围绕Docker容器的完整的生态体系。
dotCloud公司也随之快速发展壮大,在2013年年底直接改名为Docker Inc,并专注于Docker相关技术和产品的开发,目前已经成为全球最大的Docker容器服务提供商。
3.3. Google与Docker之争
而正是这种容器技术,极大的降低的软件开发的成本和难度,在维护上一个分支就足以解决问题,但是随着而来带给我们运维的问题就是,发布操作,我们可以使用编排工具来实现,而且这个必须要依靠编排工具,因为想要管理容器其实比管理应用更麻烦。运维的核心工作在于维护稳定性,如果应用程序出现故障,我们调试是很容器的,但是在容器中很可能就没有调试工具,但是如果每个镜像都自带调试工具就会让系统非常庞大。
Docker的另外一个好处就是,如果我想批量创建容器,docker run,而且如果想在一台机器上运行10个同样容器,我们只需要下载一次,就可以了。这个是由他镜像的机制来决定的。Docker镜像的底层是通过所谓分层构建,联合挂载的机制来做的。我们先做一个底层的centos镜像,随后我们想使用一个nginx,我们只需要在centos镜像上安装nginx,就形成了nginx镜像。但是,centos和nginx不是在一起的,而是两层。底层是centos,上层是nginx,两层叠加在一起,形成一个统一视图,就是nginx镜像。这个叫联合挂载,这样以后再分发的时候,镜像就没有这么大了。比如,一个机器上要运行三个容器,nginx,tomcat,mariadb底层都是基于centos构建,上次是只有nginx的层,tomcat的层,mariadb的层,我们运行的时候,只需要把centos和nginx联合,centos和tomcat联合,centos和mariadb联合,就形成了我们需要的镜像,而底层的镜像都是只读的。 但是,如果容器运行起来之后,我们想要修改容器中的内容怎么办呢,我们就需要在联合挂载栈的顶层,附加一个新层,这个层才是能读能写的,容器专有的层。但是如果我们一定要删除只读镜像中的文件怎么办呢?系统会容器中的文件他标记为不可见,而不是修改只读镜像。要修改呢,就复制一个底层。
这样一来,还有一个问题,迁移就成了问题,如果我们把一个容器迁移到另外一个宿主机上去,所有写上的或者更改的数据就没办法移动,这个叫做有状态的。所以,真正在使用容器的时候,我们不会在容器本地保留有效数据。 如果我们想持久化数据,就必须在外部挂载一个持久存储,比如clusterFS或者ceph,或者专业的存储设备。通过网络把他挂载过来,如果我们将来一不小心,服务器挂了,或者意外删除。我们只需要再找一个机器,启动一个镜像,挂载同样的存储就可以了。
我们知道,程序是由指令和数据文件组成。从另一个角度来看,容器就好像一个进程,比如我们的vim,vim编辑文件的时候,vim是进程,编辑的是文件,文件编辑完成,进程销毁,但是文件还在。启动一个容器,容器中跑着一个进程,进程终止了,数据放在外部存储上。当这个容器终止的时候,容器就可以被删除。容器就好像进程一样,有生命周期。
其实,我们可以这样,底层不管有多少主机,我们在主机上构建一个层次,如果我们想要启动一个容器,只需要向中间层发起请求,说我要启动一个容器,这个中间层会去主机上看,谁的IO更少,谁的资源更多,就把这个容器调度到这个主机上,同时分配一个存储,把生成的数据存起来,一旦任务结束,容器就删除。因此,这个组件,帮助我们把容器调度到主机只上,我们要构建NMP的时候。谁先启动呢,他们之间会有依赖关系对吧,这种依赖关系需要根据需求实现定义好,但是docker没有这个功能,我们就需要这个中间层,把程序之间的依赖关系反应在启动或者关闭时候的管理逻辑当中去。这种功能叫容器编排。docker出现之后,迅速出现了容器编排工具,比如说,docker自己的docker swarm+compose+machine,ASF的mesos,但是mesos是数据中心管理软件,他的作用是资源的统一调度,而没有容器编排,如果要实现容器编排,就需要加一个marathon。第三个就是kubernetes,简称为k8s。
而google这家公司秘密的使用容器已经有10年的历史了,当时据说每一周需要创建和销毁几十亿个容器,而docker竟然悄悄地摸到了google的门道,并且把他开源了,然后google就坐不住了。但是这个时候,docker已经有话语权了,google也说,我们要把这个技术公开出来,他不可能把自己的系统贡献出现。而容器的市场也不太平,很多其他容器管理软件,比如coreOS的rkt也出现了。然后google就在docker的背后,扶植rkt和coreos。但是后来觉得coreos在这个领域竞争不过docker,就换了策略,做容器编排工具。google自己的容器编排系统叫berg,已经把该踩的坑都踩过了,运行了10多年的系统肯定是非常稳定,因此kubernetes用golang重构了之后横空出世,一出来就一统天下,独占鳌头。占据了80%所有的市场,成为了容器编排的标准,同时还成立了CNCF。
Docker公司就好像手持金钥匙的小孩子,有所有人都羡慕的财富,却不知道怎么玩。Docker技术一直没有找到一个变现的点,让自己做大,让估值更高。后来Docker就把docker做成了社区版和企业版,后来就把社区版改名了叫Moby,把所有社区版的流量都引入了企业版,引起了众怒。主要还是商业公司docker cloud对于docker的主导权。而google为了证明自己没有控制kubernetes未来走向的意图,所以成立了CNCF,就把cncf抛给了CNCF来维护,而cncf实际上是公共组织,除了linux和google牵头,还有其他公司,比如微软,IBM等。这样就让大家对k8s追捧的程度非常高。
3.3. 容器与容器镜像的标准
然后咱们再说Docker,他在自身技术成熟以后,就抛弃了LXC,自己研发了自己的环境,自己的容器引擎,叫labcontainer。这个时候,cncf已经明确说明不带Docker玩了,那么谁来做这个容器引擎的标准化呢,这个时候,机会来了,让docker来做这个,做一个软件,并且开源出来,所以后来就出现了runC,这个才是目前容器运行时的标准。镜像也有标准,叫OCF。
- OCI Open Container Initiative,由Linux基金会主导于2015年6月创立,旨在围绕容器格式和运行时指定一个开放的工业化标准
- containers two specifications the runtime specification(runtime-spec) the image specification(image-spec)
- the runtime specification outlines how to run a “filesystem bundle” that is unpacked on disk at a high-level an OCI implementation would download an OCI image then unpack that image into an OCI runtime filesystem bundle
- runC
- OCF:Open Container Format
- runC is a CLI tool for spawning and running containers according to the OCI specification containers are started as a child process of runC and can be embedded into various other systems without having to run a daemon
- runC is built on libcontainer,the same container technology powering millions of docker engine installations
那么docker专门提供了一个容纳容器镜像的站点,叫做docker hub,这里可找到大多数的容器镜像。