1. 概述
在我们传统的监控系统中,自动发现和主动注册是两个步骤
- 自动发现:服务器去某个网段扫描符合条件的机器,然后把他加入到我们的监控列表中
- 主动注册:客户端在启动某些符合条件的进程之后(比如zabbix-agent),主动去服务端注册自己的信息,然后加入到我们的监控列表
而prometheus的监控方式主要是服务器端主动去客户端采集数据,客户端(一般说是exporter)通过http(s)暴露指标,所以他没有主动注册这个功能。我们只能通过服务器自动发现去主动的采集客户端信息。
我们在前面的demo中,配置过了配置文件的scrape_configs参数,scrape就是采集的意思,我们采集的都是静态的内容,也就是static_configs,我们会直接把要采集的endpoint通过IP地址的方式采集过来。
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
实际上,在官方网站中,还有非常多的采集方式,或者叫做采集目标,比如:
# List of Azure service discovery configurations.
azure_sd_configs:
[ - <azure_sd_config> ... ]
# List of Consul service discovery configurations.
consul_sd_configs:
[ - <consul_sd_config> ... ]
# List of DNS service discovery configurations.
dns_sd_configs:
[ - <dns_sd_config> ... ]
# List of EC2 service discovery configurations.
ec2_sd_configs:
[ - <ec2_sd_config> ... ]
# List of file service discovery configurations.
file_sd_configs:
[ - <file_sd_config> ... ]
# List of DigitalOcean service discovery configurations.
digitalocean_sd_configs:
[ - <digitalocean_sd_config> ... ]
# List of Docker Swarm service discovery configurations.
dockerswarm_sd_configs:
[ - <dockerswarm_sd_config> ... ]
# List of GCE service discovery configurations.
gce_sd_configs:
[ - <gce_sd_config> ... ]
# List of Kubernetes service discovery configurations.
kubernetes_sd_configs:
[ - <kubernetes_sd_config> ... ]
# List of Marathon service discovery configurations.
marathon_sd_configs:
[ - <marathon_sd_config> ... ]
# List of AirBnB's Nerve service discovery configurations.
nerve_sd_configs:
[ - <nerve_sd_config> ... ]
# List of OpenStack service discovery configurations.
openstack_sd_configs:
[ - <openstack_sd_config> ... ]
# List of Zookeeper Serverset service discovery configurations.
serverset_sd_configs:
[ - <serverset_sd_config> ... ]
# List of Triton service discovery configurations.
triton_sd_configs:
[ - <triton_sd_config> ... ]
从名字上,我们就可以看出来,他支持直接从各种软件中读取信息,从而实现自动化监控。我们这套课程主要讲的是三种
- consul_sd_configs: 今天要讲的内容,我们就是要把endpoint注册到consul中,然后让prometheus去consul中查询要监控的目标
- file_sd_configs: 把配置写到另外的文件当中,实现分类管理,这个好理解,我们后面一带而过
- kubernetes_sd_configs: 最后集成kubernetes的时候再讲,可以直接去etcd中拿信息进行监控
2. consul
consul是HashiCorp的产品,HashiCorp是由Mitchell Hashimoto和Armon Dadgar联合创办,总部位于美国旧金山,致力于为企业提供服务,通过数据中心管理技术研发,让开发者通过工具构建完整的开发环境,提高开发效率。他们还有一些知名的产品
- Vagrant: 虚拟环境,轻量级的虚拟机
- Terraform:IaC工具,用于构建基础架构,和ansible这种软件的集成也非常流畅
- Packer:构建镜像的工具
- Vault:密码管理工具
- Nomad:集群调度工具,数据中心级别
2.1. 架构
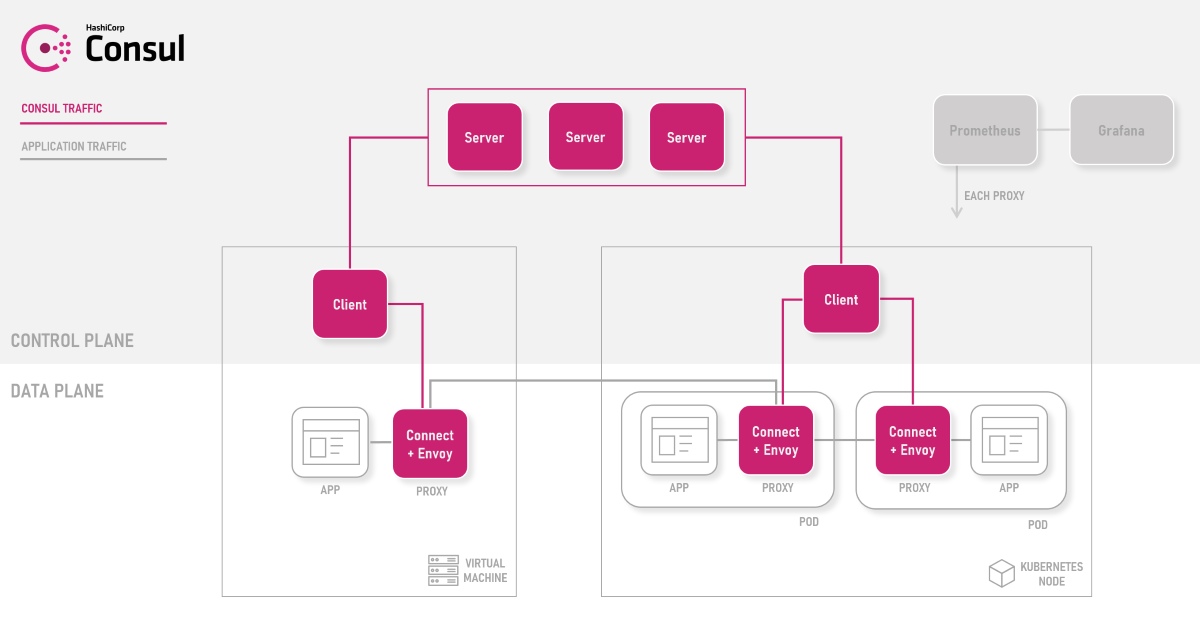
consul是一个服务注册中心,功能上和zookeeper,etcd并称为三大注册中心,是目前微服务时代比较流行的解决方案之一。Consul是用golang语言开发的,非常轻量,效率也非常高。我们这次demo只用一个单实例的服务端,后面讲微服务的时候,我们再说他的集群架构。
2.2. 下载与安装
我们这里使用的是v1.8.3,使用Docker启动
docker run --name consul -d -p 8500:8500 consul
或者使用命令行启动
consul agent -dev -ui -client 0.0.0.0
说明:consul秉承了golang语言开发的特点,所有的功能都在一个可执行文件当中了
这个时候打开浏览器就可以看到界面了,http://localhost:8500
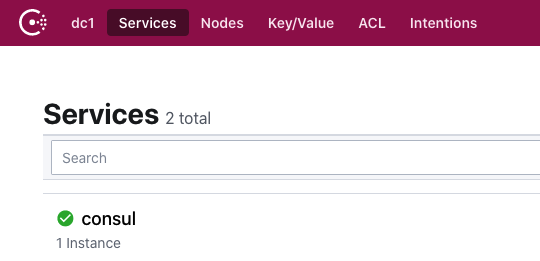
2.3. 添加一个node_exporter节点
假设我们已经在机器上安装好了node_exporter,暴露在9100端口,我们使用curl向consul中提交一个endpoint的注册请求。在consul中,所有的endpoint,也就是exporter都是被注册为service的。
curl -X PUT -d '{
"id": "node-exporter",
"name": "node-exporter-172-16-0-1",
"address": "172.16.0.1",
"port": 9100,
"tags": ["master1"],
"checks": [{"http": "http://172.16.0.1:9100/metrics", "interval": "5s"}]
}' http://localhost:8500/v1/agent/service/register
这个时候,我们可以在界面上看到多出了一个service
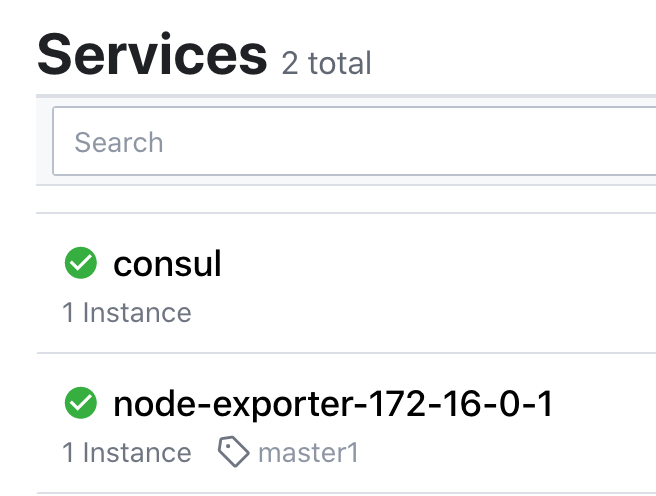
Instance的信息
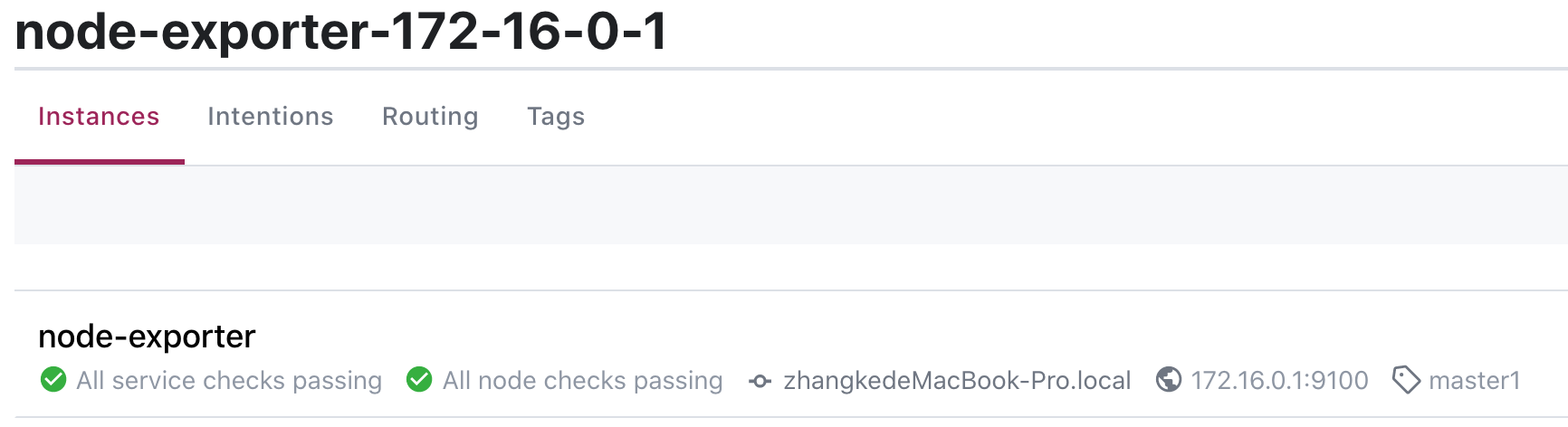
2.4. prometheus采集consul信息实现自动发现
我们在prometheus的配置文件中增加consul的服务发现
...
- job_name: 'consul-prometheus'
consul_sd_configs:
- server: 'localhost:8500'
services: []
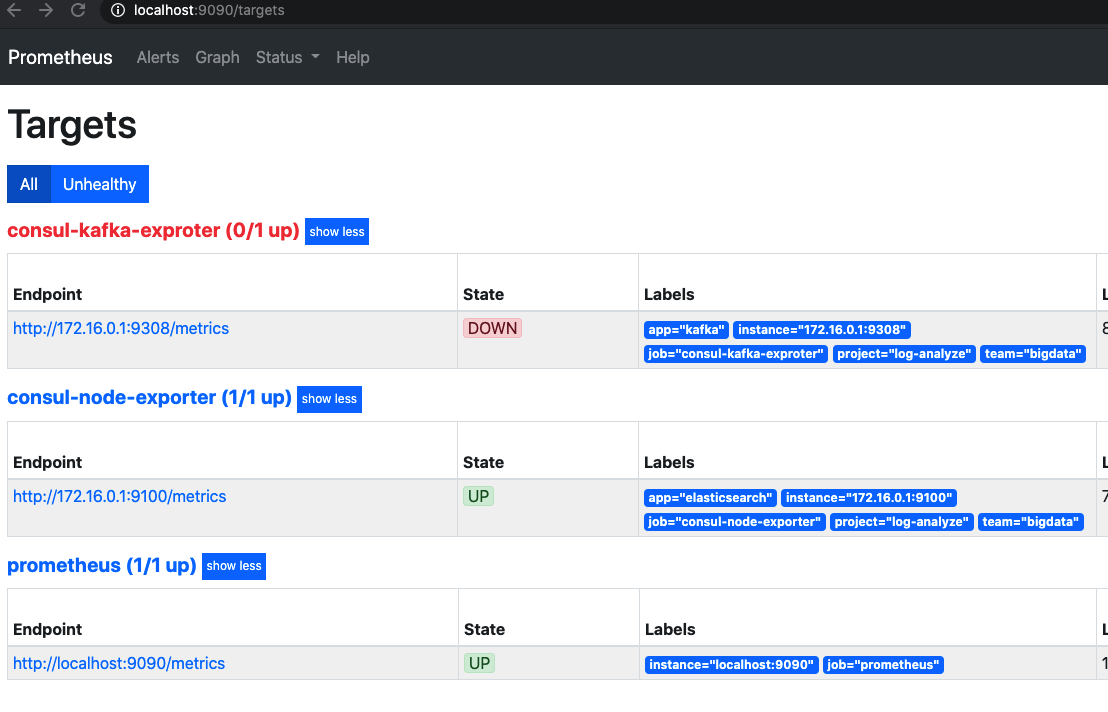
然后访问prometheus的9090端口,点击target选项
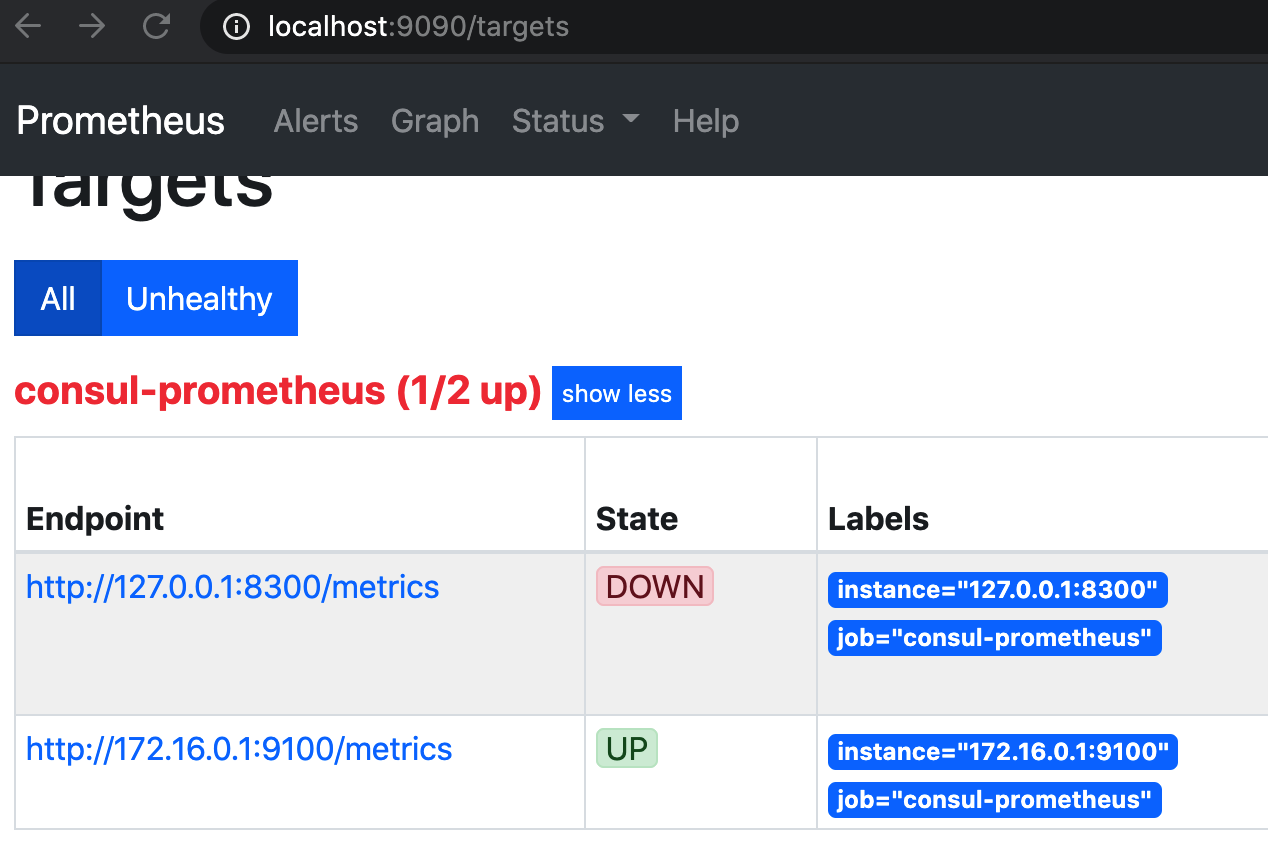
2.5. 通过relabel来匹配我们所需要的
我们发现除了我们所需要的metrics之外,竟然还多了一个consul的配置,这是我们不需要的,我们可以通过relabel方式来匹配我们所需要的。
...
- job_name: 'consul-prometheus'
consul_sd_configs:
- server: 'localhost:8500'
services: []
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*master1.*
action: keep
重启prometheus之后发现,consul已经没有了,我们来说说咱们配置的relabel的这几行的意思。
-
relabel_configs:就是需要修改label,
label是K-V的数据,而consul中没有label,只有tag和meta,tag是单值的。我们刚才传值的时候给被监控节点传递的是"tags": ["master1"],。 - source_labels:这里的
__meta_consul_tags是一个系统的内置变量,(所有的内置变量在这里),我们要匹配的是consul的tag - regex:是正则匹配的意思,这里有个小坑,这里的正则是RE2 regular expression,不是我们平时的perl类型的正则,想匹配tag是master1的,必须这样写
.*master1.* - action:匹配到了之后,就要做操作了(所有操作在这里),这里是匹配到的留下,没有匹配到的就不要了,因为service consul默认是没有标签的,所有匹配不到,就被过滤掉了
这个时候,consul服务已经没有了
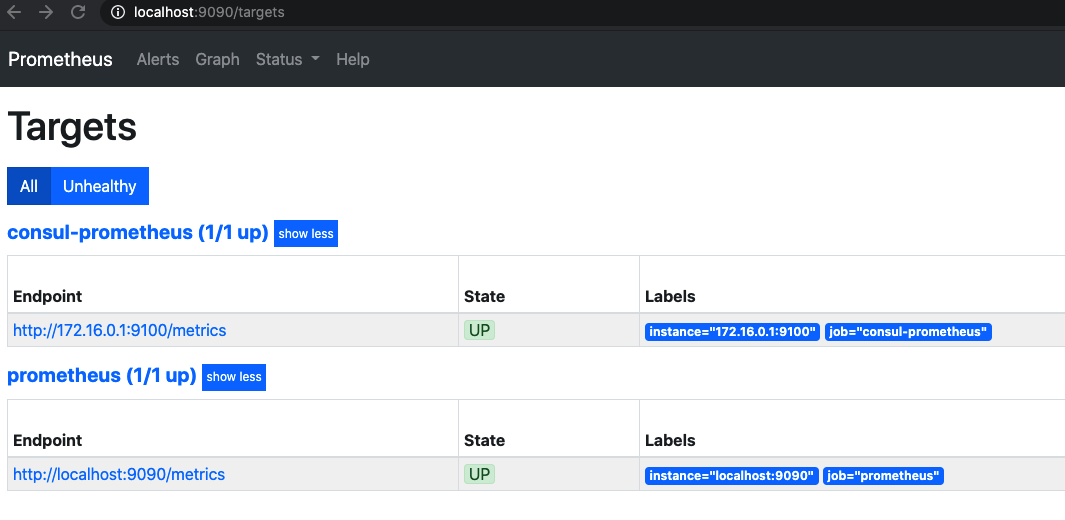
2.6. 优化注册的服务
2.6.1. 打标签
标签很重要,他是作为分配一个endpoint的重要依据,不仅是在prometheus与consul中,在alertmanager中进行报警的时候也非常重要。我们参考一下aws上的最佳实践
2.6.2. JSON文件
我们把我们要PUT的内容都写在json文件中,在使用curl的时候,直接读取这个文件就可以了,对于日后的脚本化,自动化运维非常重要。我们把刚才的内容打上标签再写成JSON文件
{
"ID": "node-exporter",
"Name": "node-exporter-172-16-0-1",
"Tags": [
"master1"
],
"Address": "172.16.0.1",
"Port": 9100,
"Meta": {
"app": "elasticsearch",
"team": "bigdata",
"project": "log-analyze"
},
"EnableTagOverride": false,
"Check": {
"HTTP": "http://172.16.0.1:9100/metrics",
"Interval": "10s"
},
"Weights": {
"Passing": 10,
"Warning": 1
}
}
上传到git上之后,下次我们在初始化某个节点的时候就可以下载这个json文件然后进行注册了。
curl --request PUT --data @node_exporter-1.json http://localhost:8500/v1/agent/service/register
# 以前的版本中需要加这个参数?replace-existing-checks=1,新版没有这个参数了,会直接覆盖原来的数据
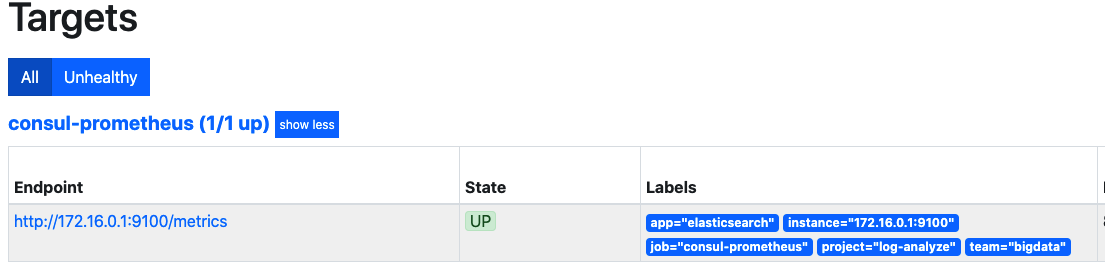
打开界面,我们发现多了几个标签
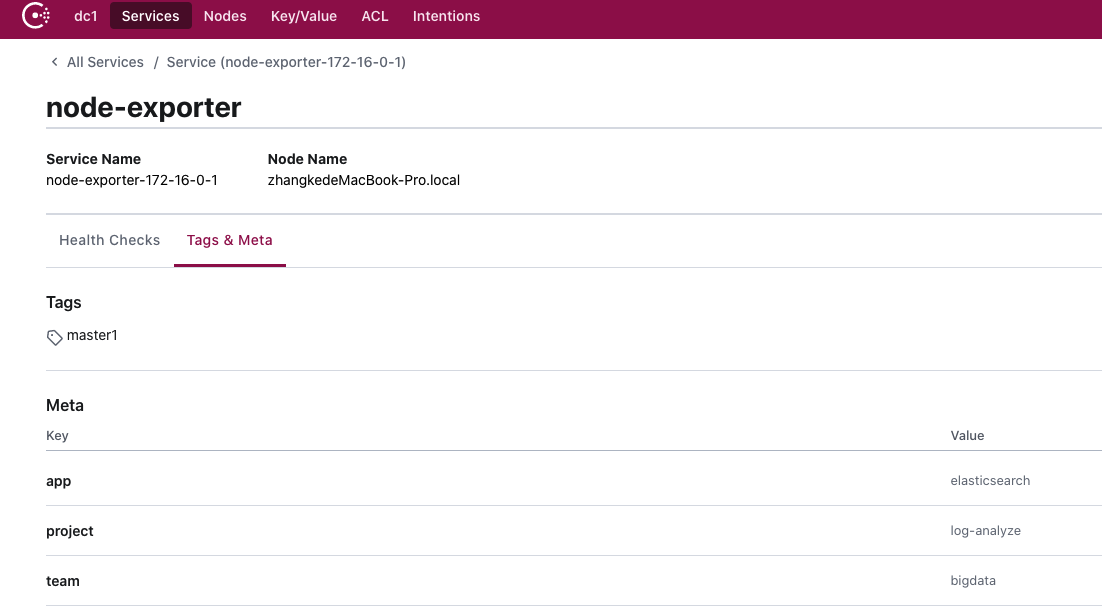
修改prometheus配置
- job_name: 'consul-prometheus'
consul_sd_configs:
- server: 'localhost:8500'
services: []
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*master1.*
action: keep
- regex: __meta_consul_service_metadata_(.+)
action: labelmap
我们增加了__meta_consul_service_metadata_的配置,匹配到的是以这个开头的标签,捕获到了之后作为新的标签使用,也就是说,系统会添加__meta_consul_service_metadata_app=elasticsearch、__meta_consul_service_metadata_team=bigdata、__meta_consul_service_metadata_project=log-analyze三个标签,经过relabel后,prometheus会新增app=elasticsearch,team=bigdata,project=log-analyze三个标签
2.6.3. 将发现的服务分类
和上面打标签的方式类似,这里我们区分服务的时候使用tag来区分,也就是对service打上tag,我们同样使用的是relabel_configs,我们创建两种不同的服务,node-exporter(node-exporter-1.json)和kafka-exporter(kafka_exporter.json)。
-
node-exporter-1.json
{ "ID": "node-exporter", "Name": "node-exporter-172-16-0-1", "Tags": [ "node-exporter" ], "Address": "172.16.0.1", "Port": 9100, "Meta": { "app": "elasticsearch", "team": "bigdata", "project": "log-analyze" }, "EnableTagOverride": false, "Check": { "HTTP": "http://172.16.0.1:9100/metrics", "Interval": "10s" }, "Weights": { "Passing": 10, "Warning": 1 } } -
kafka_exporter.json
{ "ID": "kafka-exporter", "Name": "kafka-exporter-172-16-0-1", "Tags": [ "kafka-exporter" ], "Address": "172.16.0.1", "Port": 9308, "Meta": { "app": "kafka", "team": "bigdata", "project": "log-analyze" }, "EnableTagOverride": false, "Check": { "HTTP": "http://172.16.0.1:9100/metrics", "Interval": "10s" }, "Weights": { "Passing": 10, "Warning": 1 } } -
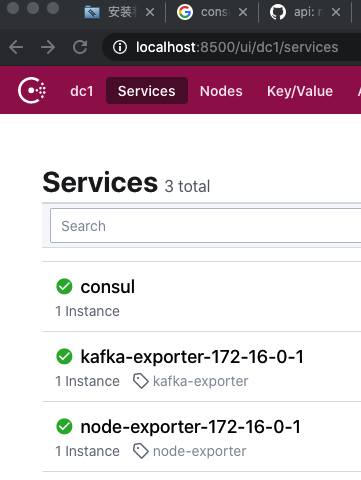
注册两个服务
curl -XPUT --data @node_exporter-1.json http://localhost:8500/v1/agent/service/register curl -XPUT --data @kafka_exporter.json http://localhost:8500/v1/agent/service/register -
界面上看一下
-
修改prometheus配置如下
- job_name: 'consul-node-exporter' consul_sd_configs: - server: 'localhost:8500' services: [] relabel_configs: - source_labels: [__meta_consul_tags] regex: .*node-exporter.* action: keep - regex: __meta_consul_service_metadata_(.+) action: labelmap - job_name: 'consul-kafka-exproter' consul_sd_configs: - server: 'localhost:8500' services: [] relabel_configs: - source_labels: [__meta_consul_tags] regex: .*kafka-exporter.* action: keep - regex: __meta_consul_service_metadata_(.+) action: labelmap -
这个时候界面上就体现出来target的分组了