概述
我们看到很多教程都是使用一台机器安装elasticsearch,然后kibana,然后各种组件全部怼到了一台机器上。有的教育机构资源比较丰富的,会找三个节点来安装一个小集群。他们主要是教大家怎样入门elasticsearch,但是我们的教程是生产级的,又是保姆级的,我们会教大家搭建一个相对稳定的架构,并且教大家怎样维护他,就像给客户做了一个完整的项目一样。但是,不积跬步无以至千里,我们要先从最基本的学起,这篇我们Demo一下单节点,三节点和一些工具的安装和配置
1. 单节点elasticsearch
-
JDK:运行elasticsearch需要jvm,所以我们需要在机器上安装java。java的 版本需要在1.8之上,如果我们从官网链接跳转下载地址,是会下载自带jdk的elasticsearch的。
- 下载地址:https://www.elastic.co/cn/downloads/elasticsearch
- 不带jdk的:https://www.elastic.co/cn/downloads/elasticsearch-no-jdk
es自带的jdk是java的最新版,目前是jdk14。大部分公司对于java的版本是有要要求的,不管是出于安全考虑还是管控的考虑,所以大家可以使用公司指定的jdk版本,先安装java,在安装es。(没有公司再用java1.6或者1.7了吧。。。。)
另外,如果我们的安装时候的系统环境比较特殊,比如非x86架构,也需要使用自己的java环境,比如我们这次实验的环境就是ARM架构(树莓派),我们就选择操作系统的镜像源中的java。
-
安装elasticsearch:根据管理方式的不一样,启动方式可能不一样
# x86版本 yum install -y https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.0-x86_64.rpm # 我用的是ubuntu 20.04 LTS for ARM,用的是这个 dpkg -i https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.0-arm64.deb -
完成后什么都不用配置就能启动了
$ systemctl start elasticsearch -
启动后测试一下
root@node1:/opt/packages/elastic# curl localhost:9200 { "name" : "node1", "cluster_name" : "elasticsearch", "cluster_uuid" : "_na_", "version" : { "number" : "7.9.0", "build_flavor" : "default", "build_type" : "deb", "build_hash" : "a479a2a7fce0389512d6a9361301708b92dff667", "build_date" : "2020-08-11T21:36:48.204330Z", "build_snapshot" : false, "lucene_version" : "8.6.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } -
当然,作为专业的人员,总是要做一些配置的,修改/etc/elasticsearch/elasticsearch.yml
# 指定监听的端口,默认是localhost network.host: 0.0.0.0 # 这个是说指定了服务器起来之后去哪发现这个集群,这里的172.16.0.1就是本机的地址 discovery.seed_hosts: ["172.16.220.11"] -
再重启一下看看是不是正常
systemctl restart elasticsearch
2. 单节点kibana
-
下载地址:https://www.elastic.co/cn/downloads/kibana
-
安装,请根据情况安装,这里米有arm版本的,我只好在我的笔记本上启了一个虚拟机
# x86版本 yum install -y https://artifacts.elastic.co/downloads/kibana/kibana-7.9.0-x86_64.rpm -
修改/etc/kibana/kibana.yml
# 监听的IP地址 server.host: "0.0.0.0" # kibana服务器显示的名字,可以不配置 server.name: "master1" # ES的地址 elasticsearch.hosts: ["http://172.16.220.11:9200"] # 忽略自签证书 elasticsearch.ssl.verificationMode: none -
启动kibana
systemctl start kibana -
打开浏览器,访问http://172.16.220.11:5601,就可以看到界面了
3. 三节点elasticsearch
-
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
-
我们在刚才的基础上修改配置文件,我们假设有三台机器,master1,master2,master3,地址分为别172.16.220.11,172.16.220.12,172.16.220.13
-
为数据创建独立的目录并且修改权限
mkdir -p /data/es/data mkdir -p /data/es/logs chown -R elasticsearch:elasticsearch /data/es/ -
master1上的/etc/elasticsearch/elasticsearch.yml
# 集群需要一个名字(必须的) cluster.name: es-enterprise-demo # 节点也需要一个名字 node.name: master1 # 节点的属性,我们可以认为是标签 node.attr.dc: 803 node.attr.row: 2 node.attr.enclosure: 3 node.attr.rack: r1 # 存数据的目录 path.data: /data/es/data # 存日志的目录(是es系统的日志,不是存放在es中的数据的日志) path.logs: /data/es/logs # 在系统启动的时候,是否首先分配所有的内存,如果我们的堆内存heap配置为系统的一半的时候,就把这个选项打开,生产环境建议打开 bootstrap.memory_lock: true # 监听的端口,建议每个机器有两个网口,这个用于通讯的使用万兆光纤 network.host: 172.16.220.11 # 服务的监听端口 http.port: 9200 # 集群发现的地址 discovery.seed_hosts: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 集群启动的时候发现集群的地址,如果没有指定,会去整个网段扫描 cluster.initial_master_nodes: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 一个集群中的N个节点启动后,才允许进行数据恢复处理 gateway.recover_after_nodes: 3 # 设置是否可以通过正则或者_all删除或者关闭索引库,默认true表示必须需要显式指定索引库名称 # 生产环境建议设置为true,删除索引库的时候必须显式指定,否则可能会误删索引库中的索引库。 action.destructive_requires_name: true -
master2上的/etc/elasticsearch/elasticsearch.yml
# 集群需要一个名字(必须的) cluster.name: es-enterprise-demo # 节点也需要一个名字 node.name: master2 # 节点的属性,我们可以认为是标签 node.attr.dc: 803 node.attr.row: 2 node.attr.enclosure: 4 node.attr.rack: r3 # 存数据的目录 path.data: /data/es/data # 存日志的目录(是es系统的日志,不是存放在es中的数据的日志) path.logs: /data/es/logs # 在系统启动的时候,是否首先分配所有的内存,如果我们的堆内存heap配置为系统的一半的时候,就把这个选项打开,生产环境建议打开 bootstrap.memory_lock: true # 监听的端口,建议每个机器有两个网口,这个用于通讯的使用万兆光纤 network.host: 172.16.220.12 # 服务的监听端口 http.port: 9200 # 集群发现的地址 discovery.seed_hosts: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 集群启动的时候发现集群的地址,如果没有指定,会去整个网段扫描 cluster.initial_master_nodes: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 一个集群中的N个节点启动后,才允许进行数据恢复处理 gateway.recover_after_nodes: 3 # 设置是否可以通过正则或者_all删除或者关闭索引库,默认true表示必须需要显式指定索引库名称 # 生产环境建议设置为true,删除索引库的时候必须显式指定,否则可能会误删索引库中的索引库。 action.destructive_requires_name: true -
master3上的/etc/elasticsearch/elasticsearch.yml
# 集群需要一个名字(必须的) cluster.name: es-enterprise-demo # 节点也需要一个名字 node.name: master3 # 节点的属性,我们可以认为是标签 node.attr.dc: 803 node.attr.row: 4 node.attr.enclosure: 6 node.attr.rack: r3 # 存数据的目录 path.data: /data/es/data # 存日志的目录(是es系统的日志,不是存放在es中的数据的日志) path.logs: /data/es/logs # 在系统启动的时候,是否首先分配所有的内存,如果我们的堆内存heap配置为系统的一半的时候,就把这个选项打开,生产环境建议打开 bootstrap.memory_lock: true # 监听的端口,建议每个机器有两个网口,这个用于通讯的使用万兆光纤 network.host: 172.16.220.13 # 服务的监听端口 http.port: 9200 # 集群发现的地址 discovery.seed_hosts: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 集群启动的时候发现集群的地址,如果没有指定,会去整个网段扫描 cluster.initial_master_nodes: ["172.16.220.11", "172.16.220.12", "172.16.220.13"] # 一个集群中的N个节点启动后,才允许进行数据恢复处理 gateway.recover_after_nodes: 3 # 设置是否可以通过正则或者_all删除或者关闭索引库,默认true表示必须需要显式指定索引库名称 # 生产环境建议设置为true,删除索引库的时候必须显式指定,否则可能会误删索引库中的索引库。 action.destructive_requires_name: true -
启动集群
systemctl start elasticsearch -
查看一下状态
curl -XGET master1:9200/_cat/health?v epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1599016520 03:15:20 es-enterprise-demo green 3 3 0 0 0 0 0 0 - 100.0%
4. 双节点kibana
-
下载地址:https://www.elastic.co/cn/downloads/kibana
-
kibana自己是带一个proxy的,但是免费版中没有,我们需要借助其他的工具来做负载均衡,比如nginx之类,我们这里安装的时候不用考虑这么多,只需要在kibana中指定所有es的地址就可以了,因为kibana的信息是存放在es之中的,默认是叫
.kibana的一个index,所以不管哪个kibana节点上看到的信息都是一样的,不管几个kibana节点都一样 -
编辑/etc/kibana/kibana.yml
master1
server.host: "172.16.220.11" server.name: "master1" elasticsearch.hosts: ["http://172.16.220.11:9200", "http://172.16.220.12:9200", "http://172.16.220.13:9200"]master2
server.host: "172.16.220.12" server.name: "master2" elasticsearch.hosts: ["http://172.16.220.11:9200", "http://172.16.220.12:9200", "http://172.16.220.13:9200"]
5. logstash简单使用
-
下载地址:
-
修改配置文件
input { file { path => "/var/log/nginx/access.log" } } output { elasticsearch { hosts => [ "localhost:9200" ] } }
6. 怎样安装插件
插件顾名思义就是为了扩展ES本身不具备的功能的时候才需要安装的,集成在ES内部的程序,随着ES的启动一起启动。而在ES和kibana的内部都提供了插件管理机制,有一套比较完整的规范,而我们安装插件的时候,只需要运行elasticsearch-plugin或者kibana-plugin,就可以轻松安装插件了。
如果一些插件是官方提供的,我们直接运行命令安装就可以(官方插件地址),如果没有的话,就需要指定插件位置,比如
-
直接安装
./bin/elasticsearch-plugin repository-s3 -
指定URL位置,指定http或者https也行
./bin/elasticsearch-plugin install com.floragunn:search-guard-7:7.8.1-43.0 ./bin/elasticsearch-plugin install https://url/to/search-guard-elasticsearch-plugin-<version>.zip -
下载到本地,指定文件位置
bin/elasticsearch-plugin install file:///path/to/search-guard-elasticsearch-plugin-<version>.zip
kibana同理。
需要注意的是,很多教程中提到了很重要的安全插件x-pack,这个插件在6.2之后就被集成到了系统之中,不用额外安装,我们只需要在配置中把xpack.security.enabled配置成true就可以了,而官方文档中,把x-pack的文件放在了security一章,我们专门找一章再说安全相关的知识。
7. 添加license
-
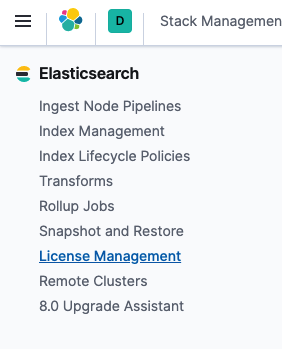
界面添加:
-
上传许可证(license),我们可以去找官方申请一个,一般来说会通过邮件的形式发送一个连接,然后我们可以下载,下载之后是一个json文件,点击Update your license
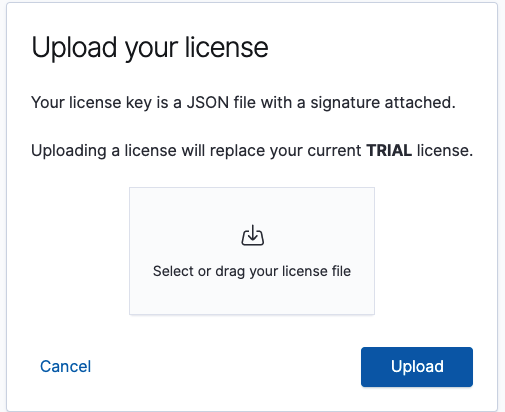
-
成功之后就会显示日期