1. 从传统监控到指标监控
监控系统从商业化的IT体系创建之初就一直伴随着整个IT体系的成长而成长,监控系统就像一个小书童一样。从另一个角度来说,IT体系的进化与发展总会触发监控体系的一次变革。

在云原生时代,监控体系也发生了本质上的变化。为了区别云原生体系下的监控产品,我们为它取了一个非常时尚的名字,叫Observability,可观测性。
时至如今,各种文章和渠道纷纷向大众宣扬可观测性,但是,我更希望从理性的角度来阐述一下可观测性。
第一,什么是可观测性。

就像云原生一样,可观测性也不过是一个概念,定义不过是别人附加给他的属性,而并不是真理,所以绝对不是一成不变的。换而言之,就和云原生的概念一样,他一直在变。
当大众还把指标监控,日志监控,链路追踪归结为可观测性的三大功能,并且每天津津乐道的谈论他们的时候,CNCF已经悄悄的把混沌工程和持续优化加了进去。
所以说,我大胆的总结一下,其实,可观测性就如直译的意思一样,就是通过各种各样的工具,对于当前云原生体系进行量化的展示和分析,以及为了提高系统稳定性而衍生出来的一系列解决方案的综合体。如果用中国话说,就是监控,只不过监控维度不一样而已。他更加的细化,更加的完善,更加的智能。
第二,你真的需要可观测性系统么?
存在就一定是有道理的,如果可观测性系统能够完全取代传统监控,那么传统监控应该很快就消失了。但是我们经常能够看到在一个公司的IT运维体系里面同时存在各种监控系统,传统监控和可观测性系统并存,针对不同的系统,使用不同的监控手段。
所以选择监控产品的时候一定要知道我们的需求是什么,到底要监控什么,要监控到什么程度,从而选择适当的产品。虽然说一些非常流行的产品可能会提高我们整体运维的B格,但是选择了不适宜的产品不但会提高运维的成本,同时还增加了项目的复杂度,很容易事半功倍。
第三,可观测性系统的架构
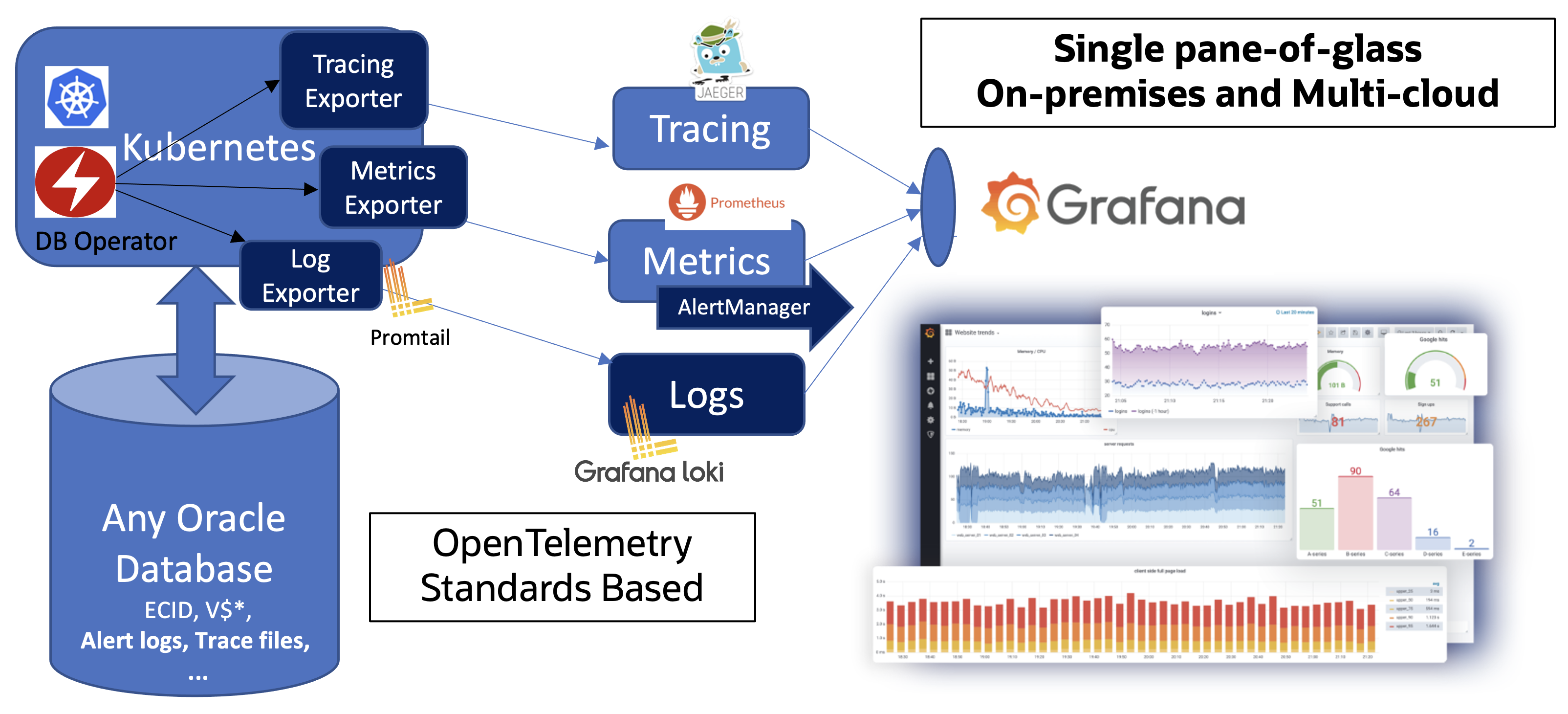
如果我们确定了需要一个可观测性系统,我们就需要针对我们的架构来进行设计了,不同的架构体系中应该选择不同的系统进行协同工作。即使同一款产品,在不同的IT体系当中,也应该使用不同的架构当中来适配。
比如,我们的监控系统和被监控的节点处在不同的网络环境中,如果我们的监控系统可以访问被监控节点,而反之不通,就需要使用主动拉取数据的方式。如果被监控的节点可以访问监控系统,而反之不通,就需要使用主动上报的模式。
第四,合理的报警

监控的目的之一就是为了报警,省去我们用眼睛去盯着系统去发现问题。
首先,报警需要合理配置,不能少报,还要减少重复,如果天天喊狼来了,狼真的来了也就没人在意了。
然后,报警是需要有人来处理的,报出来的问题需要公司内部合理的处理流程才能更加减少系统的响应时间,提高运维效率。而每个公司的流程都是不一样的,也就需要我们在懂技术的同时还要合理的设计报警处理流程。
最后,对于报警的归纳和整理,怎样预防和减少系统的错误才是我们的最终目的,我们需要对这些报警进行分析,从而更好地减少报警,提高系统稳定性。
2. Prometheus杂谈
2.1. prometheus in kubernetes
说到指标监控的工具,我们第一个想到的就是prometheus了,prometheus和kubernetes真的是一对非常好的CP。

CNCF成立之初的第一个毕业项目是kubernetes,而第二个就是prometheus,二者几乎是同时毕业的。我们目前见到的,不管是商业PaaS平台,公有云PaaS服务或者基于开源kubernetes搭建的平台,prometheus已经是标配了。比如Openshift平台,甚至默认搭建的时候会把Prometheus作为组件直接安装在集群中,并且无法修改。
但是,我们这里会从原理的角度来分析为什么他为什么能够成为标配,从而引出更多的解决方案。
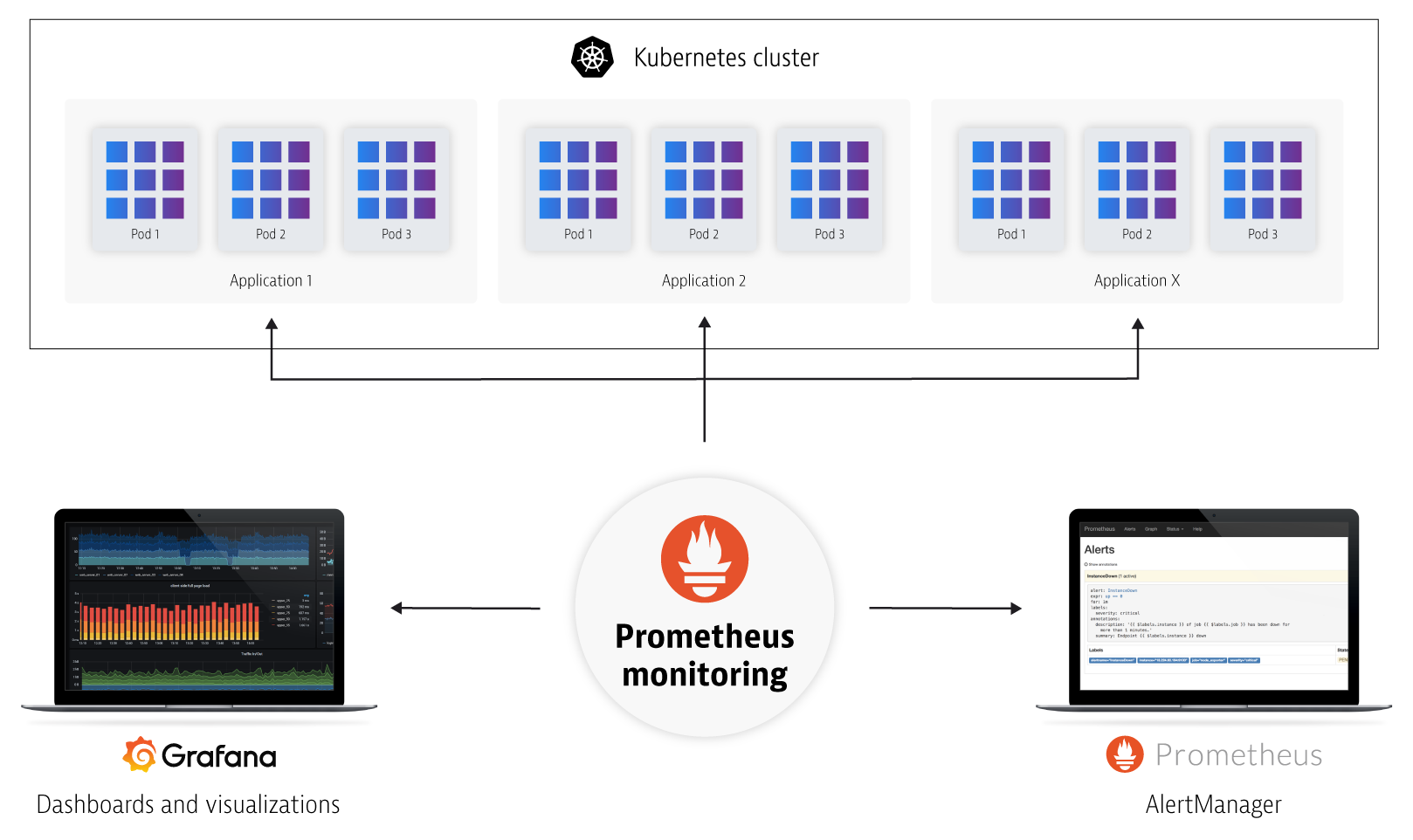
2.2. TSDB
首先,Prometheus的本质是一套数据库管理系统,他提供了数据库本身和用来查询数据库的接口,所以他既是监控系统,又是数据库。而数据库就是目前非常火热的时序数据库(TSDB)。
时序数据库是一种非常适合存储监控指标的数据库,由于他按照时间来顺序进行写入,所以写入效率非常的高。目前的主流监控系统都使用的时序数据库,特别是目前这种大规模的集群监控场景中,短时间的大量写入操作,是非常适合时序数据库的场景。
但是,时序数据库的老大并不是prometheus,他只是更加契合而已。最早的时序数据库是RRDTool,而最有名的时序数据库是Influxdb。本着后浪推前浪的原则,prometheus使用Golang开发,并且绑定kubernetes这个大腿,从而直接把一些没有底蕴的前浪直接拍在了沙滩上,甚至已经超越influxdb成为了云原生架构中的老大。

2.3. 整个市场对于prometheus的推崇
然而,我们知道,任何工具都有其适用的场景,虽然在kubernetes环境中,prometheus当仁不让成为王者,但是对于时序数据库来说,他的使用场景不仅仅是容器化环境中的监控,在其他领域,比如LoT领域,Influxdb依然是首选,他的经典架构TIGK可说是不二之选。但是我们这套课程是以prometheus为核心,下面我来介绍几种围绕prometheus展开的监控方案。
第一类,为了增加prometheus的集群功能,社区围绕着多prometheus协同工作,从而形成高可用副本的目的,开发了比如Thanos,Cortext等工具。Cortext是grafana lab,也就是prometheus的项目发起者所在的公司发起的另外一个项目。而Thanos则是我们这期的重点,目前诸如Openshift,Kubesphere都使用了部分Thanos组件来扩展功能。
第二类,为了让prometheus更加的商业化而诞生出来的一些项目,比如滴滴的夜莺或者国内大部分的商业产品,他们从易用易管理的角度增加了诸如图形化管理界面,权限隔离,审计认证等功能,然后把打包好的产品卖给客户。这一类,我们通常把他们叫做prometheus的二次开发,想要二次开发,那么我们至少要会一种开发语言,这里首推的就是Golang,golang不仅可以对prometheus的功能进行扩展,我们甚至可以对prometheus本身进行二次开发,从而让他更适合我们自己的系统。
2.4. 结论
有了kubernete这个大佬的提携,蹭上了时序数据库的热点,以及整个市场对于Pormetheus的追捧,想不火都难。需要注意的是,prometheus虽然在kubernetes的环境下是最优解,但是他并不能代表整个指标监控系统,在企业中,我们依然建议因地制宜,选择领域内的最优解,形成最适合自己的监控体系。