1. 从Prometheus到Thanos
1.1. Prometheus从开源到商业之路
Prometheus项目本身的目的是为实现容器的动态环境中,对于集群和容器的指标监控。而项目也仅仅实现了这些功能。但是如果想让一个产品商业化,那么就需要考虑到企业级应用所需要的其他功能,比如认证,授权,集群,备份等等方面。
所以说,如果企业内部对于上述的商业化功能没有特别要求,我们完全可以通过其他手段来实现一些企业化要求。但是从我的经验来看,除非是互联网公司或者有资深技术专家,否则,基本上都会使用其他公司提供的,打包好的商业产品,通过购买驻场服务或者购买远程支持等手段来维护自己的指标监控集群。
这些服务提供商大致分为三类:
- 公有云厂商:他们在提供计算服务的同时,也提供这些计算能力的基础指标监控。也提供其他系统指标的接入功能,这种方式好处是省去了大量安装部署的工作,并且按需付费。不好的地方是泛用性不强,经常会强绑定一些公有云服务,而且对于混合云架构来说,成本偏高,毕竟监控数据的实时传输,对于专线的消耗还是很严重的。
- 专门提供监控服务的厂商:比如InfluxData,Datadog,Dynatrace,他们更倾向于监控系统的整体,所以底层有可能使用自己的数据库,比如InfluxdData就是使用InfluxdDB。或者agent自己开发,比如datadog的agent,然后做大之后可能会自成一派。
- 提供整体解决方案的厂商:这些厂商的卖点并不是监控产品,而是其他产品,但是监控又是不可获取的功能,他们往往会选择一些核心的项目,然后自己基于这些免费的,开源的核心项目,就比如Promehtues,来增加一些商业功能,从而打包卖个客户,就比如红帽的PaaS平台,Openshift
我们继续上面描述的第三类公司再继续说一下,这些厂商为了提高效率,往往是避免重复造轮子,会从社区挑选免费的开源的项目,特别是CNCF的项目,因为CNCF的项目是GNU协议的,完全免费。然后在项目中加入自己的一些功能,比如认证授权,或者加上漂亮的页面和自己的产品打包售卖。
产品方面当然都会选择时下比较流行的,可以长期发展的核心了,因此,Prometheus绝对是首选。但是以Prometheus为核心的其他开源项目的发展势头迅猛,这些项目在一定程度上解决了Prometheus的商业化过程中所遇到的困难,比如我们要说的Thanos,和他同类的还有Grafana的Cortext。下面我们就来看一看Thanos到底解决了Prometheus哪个方面的问题。
1.2. Thanos项目
截至到2022年4月26日,Thanos项目是CNCF基金会的孵化项目之一。

很多知名的产品都选用了Thanos来作为核心监控系统Prometheus的扩展和延申。但是并不是所有的Thanos功能都被用到,可以只用到了一部分的功能,这也是Thanos受欢迎的原因之一。他是一个非常cloudnative的产品,他把自己的功能总结为7个部分。
1.3. 架构图
我们先来看一下图。官方提供了两种架构,我们这里先说第一种。
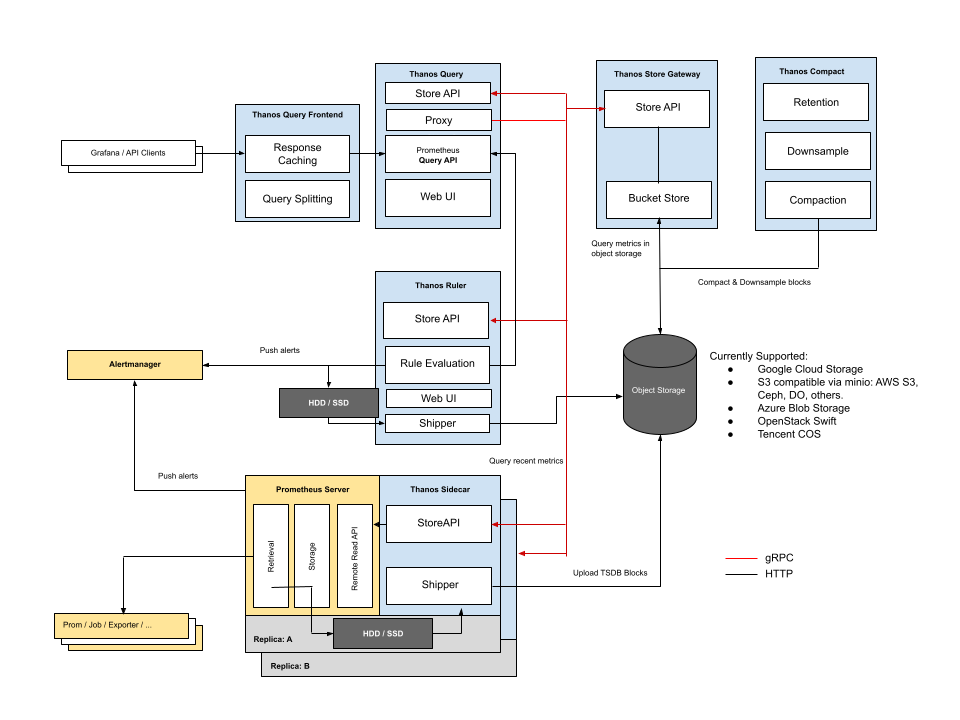
从图上可以看到,原来的prometheus架构是黄色的,被当成了和业务一样,而整个的thanos体系作为prometheus的扩展让prometheus形成了高可用的架构。每一个方块都代表了一个container,在thanos的sidecar部分,thanos真的作为sidecar和proemtheus运行在一个pod里面,作为整个体系的核心提供监控指标的采集功能。而ruler功能不再由prometheus提供,由Thanos提供,整体上对原有的prometheus是有一定的结构侵入和取代的。
第二种架构如下
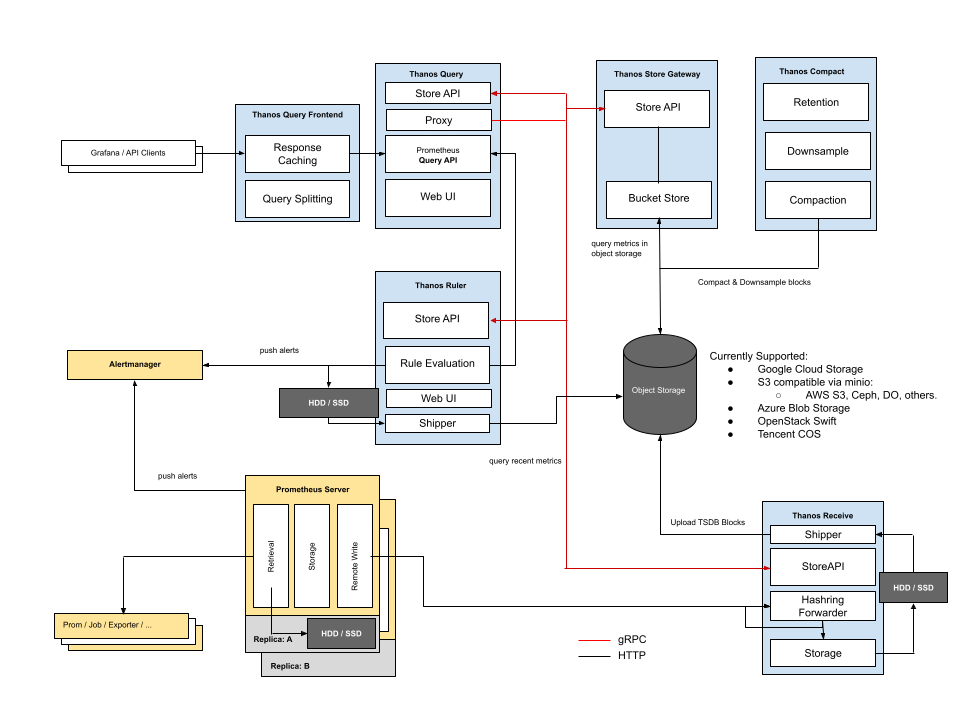
第二种架构通,thanos收集prometheus指标的方式不再是通过sidecar,而是通过prometheus的remote write功能,把指标写入thanos,这边就对网络有一定的压力了,比如我们采用的15s一次的采集速度进行exporter的metrics采集的话,如果指标不能及时的传入thanos receiver的话,会对prometheus本身造成非常大的压力。
1.4. 从Prometheus到Thanos
我们看过了thanos的图再看一下thanos到底解决了prometheus的什么问题呢?一言以蔽之,就是集群功能。
集群这个概念大的很,我们具体来说一下从图中能够一眼看出来的集群功能。
- Prometheus的黄色方块下面写着replica:A和replica:B,这两个副本实际上做的是同一件事,那就是采集指标,确切的说,采集同一个指标,生成两份tsdb,理论上这两个tsdb的内容是完全相同的,他们的内容通过sidecar或者receiver被thanos托管之后,由thanos query来统一的进行查询,即使某一个prometheus挂掉,一段时间内无法采集到数据,thanos query所展示的指标上也不会出现难看的断点。
- Thanos的storage gateway实际是对底层对象存储的一个逻辑整合,thanos不用关心底层的对象存储到底是什么,只要向storage gateway中丢数据就好了,而对象存储这种介于存储业务数据和归档数据之间的数据非常适合存储时序数据库中的数据,性价比极高。如果我们使用的是公有云的环境,那么S3这种SLA99.995%,价格超低,速度又适中的存储绝对是上上之选。
- Thanos的ruler和prometheus配置文件中的ruler遵循完全相同的匹配规则,可以无缝进行切换。由于我们的Thanos ruler去query或者对象存储中去匹配报警规则,即使某一个prometheus挂掉了,产生误报的几率也非常低。
- Thanos query frontend为查询提供了缓存机制,只要是查过一次的数据,第二次查起来简直快的不要不要的。
2. 我们和Thanos
Thanos项目应该是目前比较稳定的prometheus集群化项目了,当然,诸如cortext或者自研的一些产品都可以作为参考。而TSDB除了prometheus还有诸如influxdb,VictorMetrics等其他的方案,我们这里先把Thanos给大家讲明白,其他的后面有机会再说。
我们这一套thanos的培训会分四个阶段。
- 在实例上,搭建一套单机的thanos系统,主要是让大家熟悉thanos的各个组件
- 在实例上搭建一套集群的thanos系统,架构选用架构图一,这个为了让大家明白各个组件在集群中怎么工作
- 无缝修改架构,从架构图一到架构图二,这个为了让大家熟悉这两种方式的优劣
- 在kubernetes集群中搭建thanos来辅助prometheus,这个只要各位熟悉前面的,到了这里就是体力活了,做一个yml工程师