1. 介绍
1.1. TIGK
在云环境中的工作的运营者特别依赖监堆栈所提供的资源的持续可见性和告警,使其成为云的基础组件。希望利用OpenStack等开源云环境的企业数量在不断增加,这带来了对开源监控解决方案的需求。
随着容器时代的到来,业务软件架构正在向微服务架构发展和调整。微服务架构下的软件不断提供更多的API接口来实现方便灵活的调度。在这种背景下,目前一些系统监控软件(比如Zabbix,nagios)就略显笨重,使用灵活度上有所不足。
Telegraf Influx Grafana Kapacitor(TIGK)是在公有云(AWS,Aliyun,Azure,google云)或者私有云(OpenStack)云中使用的解决方案之一,可以Ansible部署。TIGK从系统CPU、RAM和I / O(网络和磁盘)捕获、存储、显示和触发警报提示。
1.2. 名词解释
-
influxdata:开发T,I,K产品的公司,最知名的当然还是influxdb
- T:Telegraf,安装在服务器上的agent,负责收集数据
- I:InfluxDB,时序数据库,负责高频次的写入和查询
- G:Grafana,数据展示平台,支持多种数据源
- K:Kapacitor,告警服务
2. 架构图
2.1. 整体架构
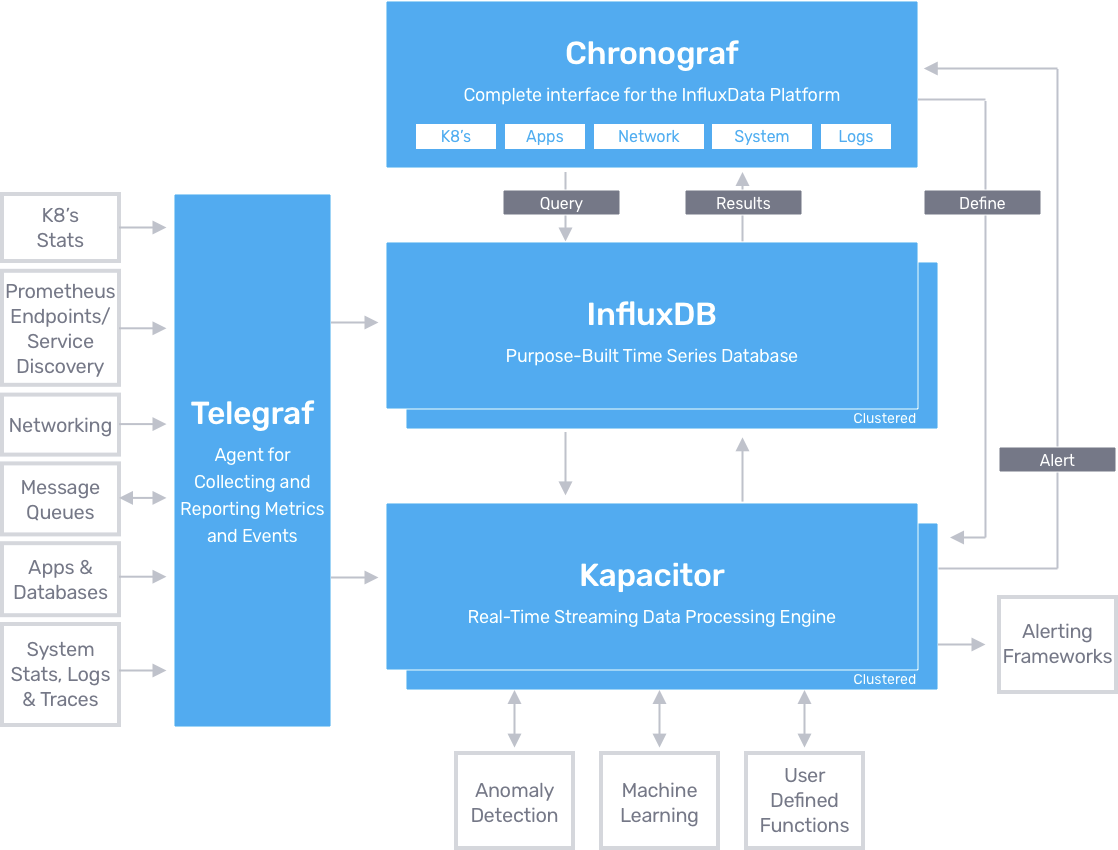
2.2. Telegraf
Telegraf是一个插件驱动的服务器代理,用于收集和报告度量指标,使用起来跟Collectd、Statsd、Logstash等软件很像。通过plugin来实现数据的input和output。Telegraf通过插件可以直接从它正在运行的系统中获取各种指标,从第三方API获取指标,甚至通过Statsd和Kafka的消费者服务来接收度量指标。它还提供了输出插件,将指标发送到各种各样的数据存储、服务和消息队列,包括InfluxDB,Graphite,OpenTSDB,Datadog,Librato,Kafka,MQTT,NSQ和很多其他组件。Telegraf目前支持80多种输入插件,但目前还没有直接获取虚拟机度量指标的插件,有个cloudwatch插件可以从Amazon CloudWatch获取度量指标。
Telegraf的特性:
-
Go语言编写,编译为一个二进制文件,没有外部依赖。
-
占用内存小,通过插件开发人员可轻松添加input和output来支持其他服务的扩展
-
支持众多流行服务大量插件,满足主流监控需求。
参考:官方文档
2.3. InfluxDB
InfluxDB是一个时间序列数据库,从创建之初就考虑到处理高的写和查询负载。InfluxDB是一个定制的高性能数据库特别用来存储时间戳数据,包括DevOps监控、应用指标、物联网传感器数据,实时分析。为了节省机器上的存储空间,可以配置InfluxDB保持数据的时间长度,自动到期和从系统中删除任何不需要的数据。InfluxDB还提供与数据交互的SQL的查询语言。
InfluxDB的特性:
为时间序列数据专门定制的高性能数据存储。TSM引擎允许高速接收和数据压缩。完全go语言编写。编译成一个单一的二进制,没有外部依赖。
简单,高效写入和查询HTTP(S) APIs。插件支持其他数据获取协议如Graphite、collectd和OpenTSDB。定制的类SQL的查询语言方便查询汇总的数据。 通过标签为快速查询和有效查询进行索引,保留政策有效地使失效数据自动过期。连续查询自动计算聚合数据,使频繁查询效率更高效。
内置的web管理界面。虽然开源版本不支持集群服务,但可以通过HAProxy + Influx Relays实现InfluxDB的高可用,这种架构已经被实现到OpenStack-Ansible Playbook中。此高可用性开源监视堆栈的配置可以在这里找到。
参考:官方文档
2.4. Chronograf/Grafana
Chronograf是管理员用户界面和平台可视化引擎。它使你的基础设施的监视和告警变得易于设置和维护。它使用起来很简单,包括模板和库,可以让您快速构建仪表板,实现数据的实时可视化,并且可以轻松创建告警和自动化规则。
在TICK套件中,Chronograf可以被开源软件Grafana所替代,它们的功能类似,但后者更成熟些。Grafana支持Elasticsearch、InfluxDB等多种数据源,目前部署时常用Grafana替代Chronograf,此时运维栈变为TIGK。
Grafana是一个功能齐全的度量仪表盘软件,支持从多种数据源读取数据用图表显示,界面美观,有冲击力,功能设计方便实用。多用于可视化基础实施和应用分析的时间序列数据,也可应用在其它领域,包括工业传感器、家庭自动化、天气和过程控制。
Grafana的特点:
功能强大,展示监控数据就是小菜一碟,支持8种内置图表类型,可为不同类型的数据选择不同类型的图表进行展示;
丰富的数据源接口,Elasticsearch、InfluxDB等各种数据,可通过插件扩展
丰富的API接口,方便自动化程序调用;
监控dashboard 导入、导出,这个功能比较实用,做好一个比较满意的展示面板,导出后主要修改一下里面的IP等信息,通过导入,其它主机的展示全部搞定。
支持告警,但功能相对较简单,目前只有graph图表支持告警,也只有Graphite,Prometheus,InfluxDB和OpenTSDB四种数据源支持告警。
参考:官方网站
2.5. Kapacitor
Kapacitor是时序数据分析、处理引擎。它可以处理来自InfluxDB的流数据和批量数据。Kapacitor允许插入用户自定义的逻辑或用户自定义的函数来处理基于动态门限的告警,匹配模式指标,计算统计异常,并根据这些告警执行特定动作,比如动态负载均衡。Kapacitor支持Email,HTTP,TCP,HipChat,OpsGenie,Alerta,Sensu,PagerDuty,Slack等多种方式告警。
Kapacitor的特性:
可以处理流数据和批量数据;
按计划从InfluxDB查询数据,或通过line协议从InfluxDB接收数据;
使用InfluxQL对数据做各种转换;
将转换后的数据存回InfluxDB;
添加用户自定义函数检测异常;
与HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack等集成。
参考:官方文档
3. 资源清单
3.1. 测试环境
| 组件 | 版本 | 主机 | CPU | 内存 | 磁盘 | |
|---|---|---|---|---|---|---|
| InfluxDB | 1.7.9 | 10.10.10.1 | RHEL7 | |||
| Telegraf | 1.13.3 | 10.10.10.1 | RHEL7 | |||
| Grafana | 6.6.1 | 10.10.10.1 | RHEL7 | |||
| Kapacitor | 1.5.4 | 10.10.10.1 | RHEL7 |
3.2. 生产环境
4. 安装与配置
在工作中,为了方便管理,建议大家使用RPM/DNF/DEB的方式安装
4.1. 安装与配置InfluxDB
-
下载与安装:
$ yum install -y https://dl.influxdata.com/influxdb/releases/influxdb-1.7.9.x86_64.rpm -
配置文件:
/etc/influxdb/influxdb.conf,请修改以下几个地方,其他的默认配置就好,如果修改到其他的位置,一定注意修改权限,因为systemctl默认的启动用户是influxdb。[meta] # 数据库的元数据,相当于配置文件 dir = "/var/lib/influxdb/meta" . . [data] # 数据存储的位置,建议放到独立的高性能磁盘上 dir = "/var/lib/influxdb/data" # 类似于mysql的binlog,会被频繁的读写,建议放到独立的高性能磁盘上 wal-dir = "/var/lib/influxdb/wal"注意:如果出现不能启动的情况,请查看/var/log/messages,或者使用
journalctl -u influxdb。 -
启动服务并且开机自动运行
$ systemctl start influxdb && systemctl enable influxdb -
测试:
~]# influx Connected to http://localhost:8086 version 1.7.9 InfluxDB shell version: 1.7.9 > show databases; name: databases name ---- _internal
4.2. 安装与配置Telegraf
-
下载与安装:
$ yum install -y https://dl.influxdata.com/telegraf/releases/telegraf-1.13.3-1.x86_64.rpm -
配置文件位置:
/etc/telegraf/telegraf.conf,里面的配置文件默认收集cpu,disk的信息,并写入influxdb,如果有其他的需求,请各位自行修改。 -
启动服务并且开机自动运行
$ systemctl start telegraf && systemctl enable telegraf -
测试
~]# influx Connected to http://localhost:8086 version 1.7.9 InfluxDB shell version: 1.7.9 > show databases; name: databases name ---- _internal telegraf > use telegraf Using database telegraf > show measurements name: measurements name ---- cpu disk diskio kernel mem processes swap system > select * from cpu; name: cpu time cpu host usage_guest usage_guest_nice usage_idle usage_iowait usage_irq usage_nice usage_softirq usage_steal usage_system usage_user ---- --- ---- ----------- ---------------- ---------- ------------ --------- ---------- ------------- ----------- ------------ ---------- 1581663700000000000 cpu-total ip-10-0-2-159.cn-northwest-1.compute.internal 0 0 67.41741741741244 0.15015015015012734 0 0 0 0 0.3003003003002458 32.13213213212678 1581663700000000000 cpu0 ip-10-0-2-159.cn-northwest-1.compute.internal 0 0 62.662662662666214 0.2002002002002003 0 0 0.10010010010010238 0 0.4004004004004184 36.63663663663769
4.3. 安装与配置Grafana
-
下载与安装:
$ yum install -y https://dl.grafana.com/oss/release/grafana-6.6.1-1.x86_64.rpm -
配置文件位置:
/etc/grafana/grafana.ini -
启动服务并且开机自动运行
$ systemctl start grafana-server && systemctl enable grafana-server -
登录Web控制台:
http://你的IP:3000,默认的用户名/密码是admin/admin,第一次登录需要修改密码,然后进入向导add data source,选择InfluxDB,URLhttp://localhost:8086,Databasetelegraf,点击Save & Test,出现Data source is working表示成功,点击back回到数据源的配置 -
点击左侧菜单栏的
+符号Create,点击Import,Grafana.com Dashboard的位置输入1138,在随便点击一下空白处,下面的Influx选择咱们刚才配置的Influxdb,点击Import -
来看看效果吧
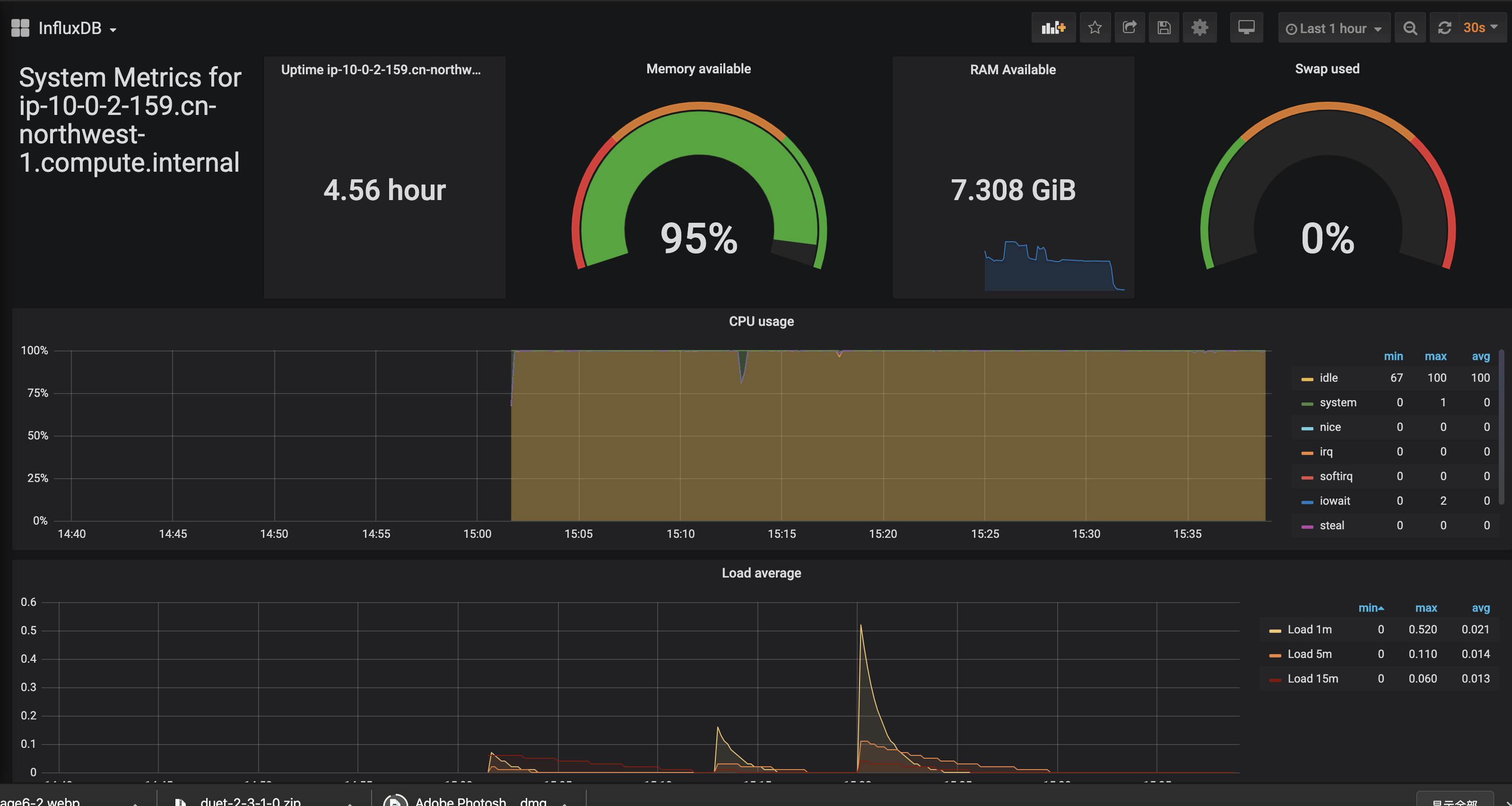
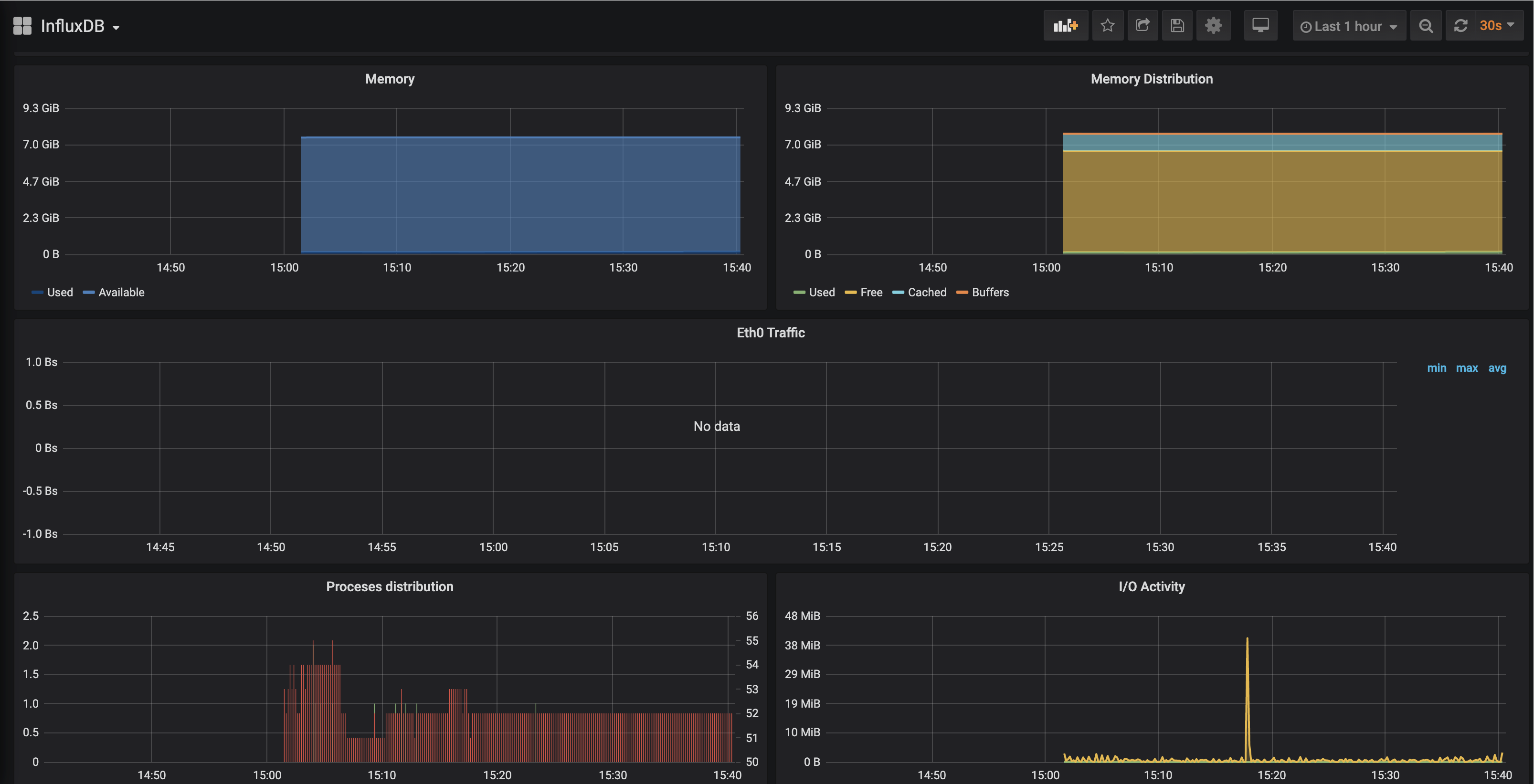
-
我们发现网络的部分是没有数据的,因为我们没有加载网络监控的配置。我们继续编辑
/etc/telegraf/telegraf.conf文件,修改下面的配置并重启服务。[[inputs.net]] ## By default, telegraf gathers stats from any up interface (excluding loopback) ## Setting interfaces will tell it to gather these explicit interfaces, ## regardless of status. ## interfaces = ["eth0"] ## ## On linux systems telegraf also collects protocol stats. ## Setting ignore_protocol_stats to true will skip reporting of protocol metrics. ## # ignore_protocol_stats = false ## -
这个时候我们再看,发现网络流量已经可以监控了

-
参考官方文档
4.4. 安装与配置Kapacitor
-
下载与安装:
$ yum install https://dl.influxdata.com/kapacitor/releases/kapacitor-1.5.4-1.x86_64.rpm -
配置文件位置:
/etc/, 如果没有特殊的需求,不需要配置任何的参数 -
启动服务并且开机自动运行
$ service kapacitor start && chkconfig kapacitor on -
创建规则
cpu_alert.tickdbrp "telegraf"."autogen" stream // Select just the cpu measurement from our example database. |from() .measurement('cpu') |alert() .crit(lambda: int("usage_idle") < 70) // Whenever we get an alert write it to a file. .log('/tmp/alerts.log') -
加载规则
kapacitor define cpu_alert -tick cpu_alert.tick -
查看规则
$ kapacitor list tasks ID Type Status Executing Databases and Retention Policies cpu_alert stream disabled false ["telegraf"."autogen"] $ kapacitor show cpu_alert ID: cpu_alert Error: Template: Type: stream Status: disabled Executing: false -
启用规则
kapacitor enable cpu_alert
5. 总结
- InfluxData是以InfluxDB出名的,个人感觉InfluxDB在时序数据库角度是超越Prometheus的,稳定性非常强,且占用资源非常少,而且http写入的方式也让数据库的兼容性非常好。
- 但是InfluxDB的社区版并不支持集群,这就让他在生产系统上上线成为了最大的障碍,花钱总是让那个老板肉疼的一件事。
- Telegraf作为Agent和Influx的结合还是非常完美的,但是Telegraf的社区并不活跃,在这个开源软件活跃的时代,光靠公司的力量想从头维护一款软件是非常困难的,最好提供统一的接口或者广泛的兼容性,或者有个好靠山:)。
- Chronograf本次没有涉及,从软件选择的时候就舍弃了,因为他只可以和InfluxDB兼容,不像Grafana兼容性广泛,在生产上使用的机会不多。
- Kapacitor的用户体现并不是很好,也许是没有买商用版的原因,报警规则非常的繁琐,报警的消息模板也非常不友好。感觉还不如Grafana自带的规则好用。
- Grafana目前真的挑不出毛病,硬要说的话,就是报警规则需要自己创建,让一般用户上手有点困难。