课程目标
- 组件的形象比喻
- Kubernetes架构
- 讨论kubernetes集群上的主要组件
- 从角色上分
- 从逻辑上分
- 组件和组件之间是怎样交互的
1. 组件的形象比喻
我们可以把各个组件比喻成一个学校中的实际形象,希望大家能够理解
| 组件名称 | 职责 | 形象 | 职责 |
|---|---|---|---|
| 节点 | master节点,worker节点 | 教学楼 | 有行政楼,1,2,3,4号教学楼 |
| api-server | 负责所有接收和分析请求,是集群的中枢 | 校长 | 对学校负责,是整个学校的协调人 |
| scheduler | 负责监控所有集群的资源使用情况 | 行政校长 | 对于整个校园的资源进行调度,分配工作 |
| controller-manager | 监控controller,保证controller的健康 | 副校长-教务 | 负责学校内各个年级的教务主任的工作 |
| etcd | 数据库 | 学生管理系统 | 存储所有信息 |
| controller | 负责pod的状态监控,保证管辖内的pod一直向着既定目标改变 | 教务主任 | 安排课程,安排老师,保证每个学生都上好课 |
| kubelet | 负责监控node上的状态是否健康 | 摄像头 | 负责监控班级内部的同学是不是上课开小差 |
| service | 服务发现和负载均衡 | 班主任 | 负责班级内部事务 |
| kubelet | 负责监控node上的状态是否健康 | 摄像头 | 负责监控班级内部的同学是不是上课开小差 |
| kube-proxy | 负责给资源分配可用的网络 | 手机 | 让大家都可以通信 |
| 网络插件 | 提供网络功能和隔离功能 | 步话机频段/手机供应商 | 联通或者电信,可以给每个人一个手机号 |
| pod | 最小调度单位 | 学生 | 我们来到学校都是为了完成学业 |
| initcontainer | 在主容器启动之前的容器 | 肚子 | 吃饱了才能上学 |
| sidecar | 辅助主容器的容器 | 书包 | 可以放上学的书,可以放水杯 |
| daemonset | 每个节点上都有 | 厕所 | 每个教学楼都有,新建教学楼就得有厕所 |
| deployment | 我们的应用都会做成deployment来服务 | 班级 | 学校都是以班级为单位进行教学任务的 |
| namespace | 集群隔离 | 学校的区域 | 教学区域,app,大操场,default,老师办公室,kube-system |
| docker | 容器运行时 | 教师 | 负责学生的学习 |
2. Kubernetes架构
- Master and worker nodes
- Controllers
- Services
- Pods of containers
- Network and policies
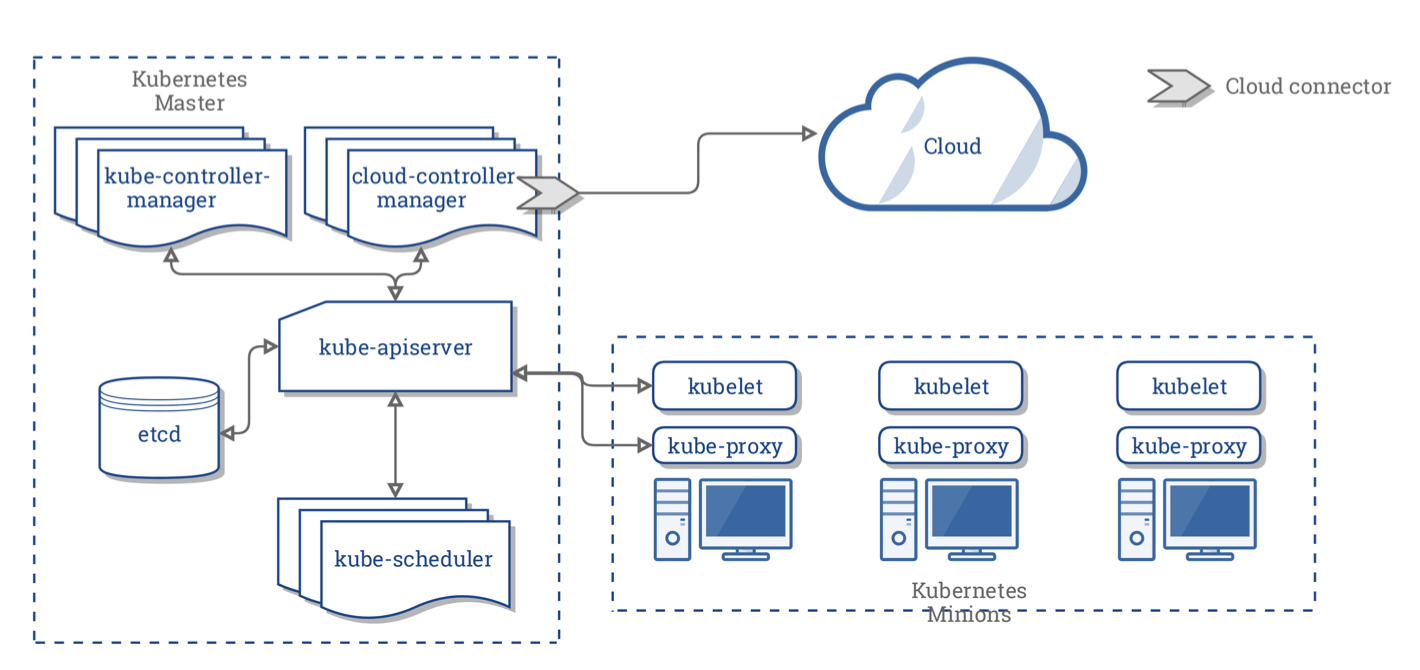
Concepts Underlying the Cloud Controller Manager
kubernetes从运维的角度来说,其实就是一个集群,组合多台主机整合成为一个大的资源池,并统一对外提供计算,存储等能力的集群,这个集群,就是找几台主机,每台主机都安装上相关的kubernetes应用程序,并通过某些具有管理功能的应用程序来协调资源,共同工作,把多个主机当一个主机来使用。
3. 从角色来分
在k8s的集群当中,主机是分角色的。k8s就是一个有中心节点的系统,他是master/nodes模型,他有一个/组节点来做master,其他节点做node节点。一般的master有三个就足够了,而nodes或者worker,负责工作。还有一种说法,把Master节点分成了控制平面control panel和数据库节点etcd,我们这里统称为master节点。
3.1. Master Node(行政楼)
Kubernetes的master节点上运行着多个集群中的服务和管理进程。在master节点上运行着kube-apiserver,kube-scheduler和etcd数据库。随着软件的成熟,为了满足某些特定的需求,就会有新的组件产生,比如cloud-controller-manager,如果kube-controller-manager发现有需要和外部程序打交道的需求事,就会把这部分任务交给cloud-controller-manager,比如Rancher,DigitalOcean这种第三方的集群管理软件。
-
kube-apiserver(校长)
有一个对外的email,xiaozhang@xuexiao.com,邮箱地址就相当于我们api-server所监听的6443。kube-apiserver是操作Kubernetes集群的核心。所有的请求,不管是内部的还是外部的请求,都是由kube-apiserver来代理的。所有的操作都是由apiserver来接受并且验证,并且他是链接到etcd数据的唯一一个组件。他为API对象验证并且配置数据(etcd中的数据),可以接受RESTful风格的请求(GET,PUT)。他作为master节点上的进程,是整个集群的入口,扮演着前端的角色,他负责共享整个集群的状态(通过查询etcd)。
-
kube-scheduler(行政校长)
会根据学校的资源情况,对学生进行分班。kube-scheduler借助于算法来决定含有容器的Pod应该被分配到哪个主机上去。scheduler会查看可以被分配出来的系统资源,然后尝试并且失败了会重新尝试部署Pod,直到成功。有很多元素会影响算法,或者我们可以使用自定的调度器。我们甚至可以把pod绑定在某个特定的节点,但由于其他设置,Pod可能仍处于挂起状态。引用的第一个设置之一是Pod是否可以在当前配额限制内部署。如果是这样,那么taints污点和tolerations容忍度、pod的标签和节点的标签一起用于确定正确的位置。
-
etcd(数据库)
学校的管理系统,储存这整个学校的情况。集群、网络和其他持久信息的状态保存在etcd数据库中,或者更准确地说,保存在b+树键值存储中。他不是查找和更改条目,而是始终将值追加到末尾。数据的先前副本随后被标记,以便将来通过回收(compaction)过程移除。它可以通过curl使用HTTP库访问,并提供可靠的监视查询。
更新值的同时请求通过kube apiserver,然后将请求以顺序的形式传递给etcd。第一个请求将更新数据库。第二个请求将不再具有相同的版本号,在这种情况下,kube apiserver将用错误409回复请求者。服务器端没有超过该响应的逻辑,这意味着客户端需要期望这一点,并在拒绝更新时采取行动。
有一个master数据库和follower。他们在不停的相互沟通,以确定谁将是master,并在发生故障时确定另一个master。虽然速度很快,而且可以快速回复,但如果使用某些工具(如kubeadm),来升级整个集群的话,就会出现一些短暂的服务终端。
-
Other Agents(kube-controller-manager教务校长)
负责教务主任的安排。kube controller manager是一个核心控制循环守护进程,它与kube apiserver交互以确定集群的状态。如果状态不匹配,管理器将联系必要的控制器以匹配所需的状态。我们有许多的控制器,例如endpoint、namespace和replication。随着kubernetes的成熟,控制器的数量已经扩大。
在v1.16的测试版中,云控制器管理器(ccm)与云外的代理交互。一旦由kube controller manager处理任务,它就会处理这些任务。这允许在不改变核心Kubernetes控制过程的情况下进行更快的更改。每个kubelet必须使用传递给二进制文件的–cloud provider external设置。您还可以开发自己的ccm,它可以作为守护程序部署为树内部署或独立的树外安装。cloud controller manager是一个可选的代理,它需要几个步骤来启用。
3.2. Worker Nodes(教学楼)
在教学楼来完成学习任务
所有工作节点都运行kubelet和kube-proxy,以及容器引擎,如Docker或rkt。部署其他管理守护程序来监视这些代理或提供Kubernetes尚未包含的服务。
kubelet与安装在所有节点上的底层Docker引擎进行交互,并确保需要运行的容器实际上正在运行。kube代理负责管理到容器的网络连接。它是通过使用iptables条目来实现的。它还具有用户空间模式,在这种模式下,它使用一个随机端口来代理流量和ipv的alpha特性来监视服务和端点。
您也可以运行Docker引擎的另一种选择:cri-o或rkt。要了解如何做到这一点,您应该查看文档。在未来的版本中,Kubernetes很可能支持其他容器运行时引擎。
Supervisord是一个轻量级的进程监视器,用于传统Linux环境中监视和通知其他进程。在集群中,这个守护进程监视kubelet和docker进程。如果失败,它将尝试重新启动它们,并记录事件。虽然不是标准安装的一部分,但有些可能会添加此监视器以添加报告。
-
Kubelet(监控摄像头)
他的职责,监控学校的运行情况。一旦出现异常,通知校长。kubelet是worker节点上更改和配置的重要工具。它接受Pod的specifications规范的API调用(一个PodSpec是描述Pod的JSON或YAML文件)。在满足规范之前,它将不停的配置本地节点。
如果Pod需要访问storage, Secrets or ConfigMaps,kubelet将确保访问或创建。它还将状态发送回kube apiserver,以便最终持久化。
-
使用PodSpec
-
将卷装载到Pod
-
下载secret
-
将请求传递到本地容器引擎
-
向群集报告pod和节点的状态。
Kubelet调用其他组件,如拓扑管理器,它使用来自其他组件的提示来配置拓扑感知资源分配,如CPU和硬件加速器。作为alpha功能,默认情况下不启用。
-
-
kube-proxy(手机)
即使有两个容器,它们共享相同的名称空间和相同的IP地址,这将由kubectl发起请求,kube-proxy负责配置。IP地址在容器启动之前分配到容器中。容器将具有类似于eth0@tun10的接口。这个IP是跟随pod整个生命周期的。
endpoint与service同时创建。注意,它使用pod IP地址,但也包括一个端口。该服务使用ipvs中的iptables将网络流量从节点高位端口连接到端点。kube-controller-manager处理监视循环,以监视endpoint和service以及任何更新或删除的需要。
此图显示了一个单pod、双containers的节点。NodePort服务将Pod连接到外部网络。
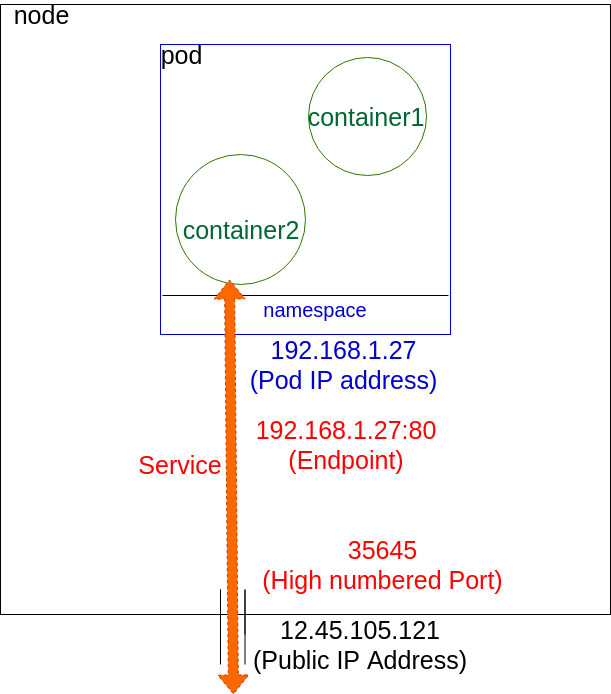
-
网络插件
尽管kube-proxy负责分配IP地址,但是kube-proxy自己不能完成这项任务,需要借助其他的软件来帮助提供网络功能和策略。kubernetes提供了一个网络接口就CNI,只要符合这个接口的软件都可以kubernetes的网络解决方案。
如果您有部署基于IaaS解决方案的虚拟机(vm)的经验,这听起来会很熟悉。唯一需要注意的是,在Kubernetes中,最低的计算单位不是容器,而是我们所说的pod。就比如,我们的openstack,他的网络组建叫neutron,而实际上内部是借助于其他网络插件来构建网络的,比如ovs或者calico。
pod是共享相同IP地址的一组位于同一位置的容器。从网络的角度来看,pod可以看作是物理主机的虚拟机。网络需要为pod分配IP地址,并且需要在任何节点上的所有pod之间提供流量路由。
在容器编排系统中要解决的三个主要网络挑战是:
-
耦合容器到容器的通信(通过pod概念解决)。
-
点对点通信。
-
外部到pod通信(由服务概念解决,我们稍后将讨论)。
-
4. 从逻辑上分
-
Pods(学生)
学校的最小调度单元。Kubernetes的整个要点是协调容器的生命周期。我们不与特定的容器交互。相反,我们能处理的最小的单元是一个Pod。有人会说一个荚豌豆。由于资源共享,Pod的设计通常遵循每个容器一个进程的架构。
Pod中的容器是并行启动的。因此,没有办法确定哪一个容器首先在Pod内可用。在某种程度上,使用InitContainers可以命令启动。要支持在容器中运行的单个进程,可能需要日志记录、代理或特殊适配器。这些任务通常由同一个pod中的其他容器处理。
每个Pod只有一个IP地址,几乎每个网络插件都有。如果一个pod中有多个容器,它们必须共享IP。为了相互通信,它们可以使用IPC、环回接口或共享文件系统。
虽然Pod通常在部署时每个应用程序容器中都有一个,但是Pod中有多个容器的一个常见原因是用于日志记录。您可能会发现术语sidecar是指专用于执行帮助器任务(如处理日志和响应请求)的容器,因为主应用程序容器可能不具备此功能。术语sidecar与ambassador和adapter一样,没有特殊的设置,但指的是包含二级吊舱的概念。
-
Controllers(教务主任)
教务主任的主要任务,就是安排学生们的学习,主任会对同类的学生分配一定的学习任务。编排的一个重要概念是使用控制器。各种控制器与Kubernetes一起发布,您也可以创建自己的控制器。控制器的简单来说就是是agent(或称为Informer)和downsteam存储。使用DeltaFIFO队列比较源和downsteam数据。循环进程接收一个obj或对象,它是来自FIFO队列的delta数组。只要delta不是Deleted类型,控制器的逻辑控制器就会创建或修改某个对象,直到它与规范匹配为止。
使用API-server作为源的Informer通过API调用请求对象的状态。数据会被缓存,来最小化API-server的负载。类似的agent是SharedInformer;对象通常由多个其他对象使用。它为多个请求创建状态的共享缓存。
工作队列workqueue使用一个键将任务分发给不同的worker。通常使用go语言内置的队列(queue)来做资源限制、延迟和时间队列。
endpoint、namespace和serviceaccount控制器分别管理pod的同名资源。
-
Services(班主任)
访问某个班级,我要一个学生帮我做卫生,班主任来班级选学生来参加扫除。由于每个对象和代理都是分离的,所以我们需要一个灵活的、可伸缩的代理,它将资源连接在一起,如果有什么东西死了,产生了替代品,它就会重新连接。每个服务都是一个微服务,处理特定的通信量,例如单个NodePort或LoadBalancer,以在多个pod之间分发入站请求。

服务还处理入站请求的访问策略,这对于资源控制和安全性都很有用。
-
把Pod连接在一起
-
向Internet公开播客
-
解耦配置
-
定义Pod访问策略。
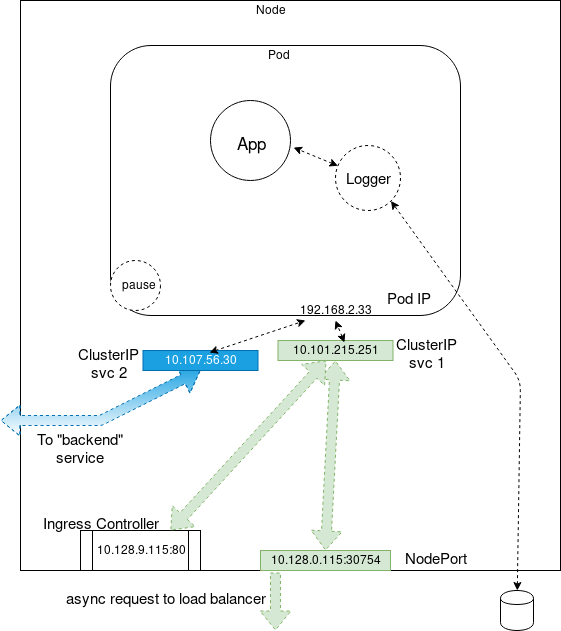
Service Network(做卫生)
ClusterIP的方式,实际上是由老师来指定学生做卫生。
NodePort的方式,老师把值班表贴在的班级的门口。
Node
节点是在集群外部创建的表示实例的API对象。虽然主节点必须是Linux,但工作节点也可以是Microsoft Windows Server 2019。一旦节点安装了必要的软件,它就会被接收到API服务器中。
现在,您可以通过传递join,创建一个带有kubeadm init和worker节点的主节点。在不久的将来,可以加入辅助主节点和/或etcd节点。
如果kube apiserver在5分钟内无法与节点上的kubelet通信,则默认的NodeLease将安排删除该节点,并且NodeStatus将从ready更改。一旦重新建立连接,播客将被逐出。它们不再被集群强制移除和重新调度。
每个节点对象都存在于kube-node-lease命名空间中。要从集群中删除节点,首先使用kubectl delete node将其从API服务器中删除。这将导致吊舱被疏散。然后,使用kubeadm reset删除集群特定信息。您可能还需要删除iptables信息,这取决于您是否计划重新使用该节点。
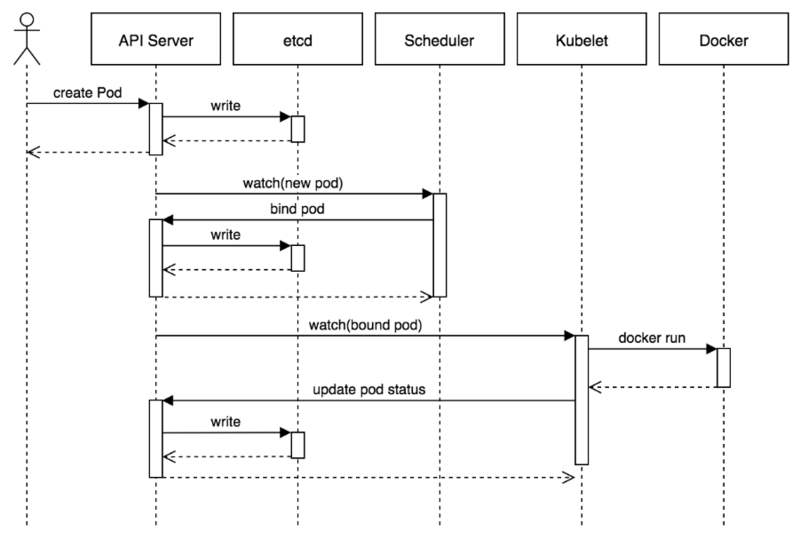
API Call Flow