课程目标
- ReplicaSet
- Deployment概念
- Deployment清单文件详解
- 对Deployment扩容和缩容
- 滚动更新和回滚
1. ReplicaSet
ReplicaSet 是下一代的 Replication Controller。 ReplicaSet 和 Replication Controller 的唯一区别是选择器的支持。ReplicaSet 支持新的基于集合的选择器需求。而 Replication Controller 仅支持基于相等选择器的需求。
1.1.怎样使用 ReplicaSet
大多数支持 Replication Controllers 的kubectl命令也支持 ReplicaSets。但rolling-update 命令是个例外。如果您想要滚动更新功能请考虑使用 Deployment。rolling-update 命令是必需的,而 Deployment 是声明性的,因此我们建议通过 rollout命令使用 Deployment。
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制。 当您使用 Deployment 时,您不必担心还要管理它们创建的 ReplicaSet。Deployment 会拥有并管理它们的 ReplicaSet。
1.2. 什么时候使用 ReplicaSet
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,我们建议使用 Deployment 而不是直接使用 ReplicaSet,除非您需要自定义更新业务流程或根本不需要更新。
这实际上意味着,您可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义您的应用。
1.3. ReplicaSet 的替代方案
-
Deployment (推荐) Deployment 是一个高级 API 对象,它以 kubectl rolling-update 的方式更新其底层副本集及其Pod。 如果您需要滚动更新功能,建议使用 Deployment,因为 Deployment 与 kubectl rolling-update 不同的是:它是声明式的、服务器端的、并且具有其他特性。 有关使用 Deployment 来运行无状态应用的更多信息,请参阅 使用 Deployment 运行无状态应用。
-
裸 Pod 与用户直接创建 Pod 的情况不同,ReplicaSet 会替换那些由于某些原因被删除或被终止的 Pod,例如在节点故障或破坏性的节点维护(如内核升级)的情况下。 因为这个好处,我们建议您使用 ReplicaSet,即使应用程序只需要一个 Pod。 想像一下,ReplicaSet 类似于进程监视器,只不过它在多个节点上监视多个 Pod,而不是在单个节点上监视单个进程。 ReplicaSet 将本地容器重启的任务委托给了节点上的某个代理(例如,Kubelet 或 Docker)去完成。
-
Job 使用Job 代替ReplicaSet,可以用于那些期望自行终止的 Pod。
-
DaemonSet 对于管理那些提供主机级别功能(如主机监控和主机日志)的容器,就要用DaemonSet 而不用 ReplicaSet。 这些 Pod 的寿命与主机寿命有关:这些 Pod 需要先于主机上的其他 Pod 运行,并且在机器准备重新启动/关闭时安全地终止。
2. Deployment
2.1. 概念
Deployment与其他对象一样,可以从YAML或JSON规范文件进行部署。当添加到集群中时,控制器将自动创建一个副本集ReplicaSet和一个Pod。容器的配置和应用程序可以通过更新进行修改,更新生成一个新的副本集,然后生成新的pod。
更新后的对象可以作为一个整体来更新,或者滚动更新。大多数更新可以通过编辑YAML文件并运行kubectl apply来配置。您也可以使用kubectl edit来修改正在使用的配置。保留以前版本的副本集,并且还可以回滚返回到以前的配置。
我们还将更多地讨论Label。在Kubernetes中,标签对于管理是必不可少的,但它不是API资源。它们是用户定义的键值对,可以附加到任何资源,并存储在元数据中。标签用于查询或选择集群中的资源,允许对集群进行灵活而复杂的管理。
由于标签是任意的,您可以选择开发人员使用的所有资源,或属于某个用户的所有资源,或任何附加的字符串,而不必知道这些资源的种类或数量。
2.2. Deployment
replicationcontroller(RC)确保一次运行指定数量的pod副本。replicationcontroller还使您能够执行滚动更新。但是,这些更新是在客户端管理的。如果客户端失去连接,并且可能使群集处于非计划状态,则会出现问题。为了避免在客户端扩展复制控制器时出现问题,在apps/v1API组中引入了一个新资源:Deployments。
部署允许以指定的速率对播客进行服务器端更新。可以用于金丝雀和其他部署模式。部署生成副本集,它提供比replicationcontroller更多的选择功能,如matchExpressions。
$ kubectl create deployment dev-web --image=nginx:1.13.7-alpine
deployment "dev-web" created
2.3. 对象之间的关系
下图中,我们看到从容器角度来划分的对象关系,kubernetes是不直接管理pod的,而是交给了deployment
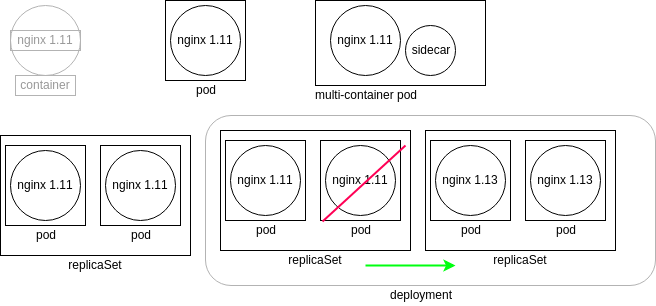
上面的盒子和形状是有逻辑的,它们表示控制器或监视循环,作为kube-controller-manager的一个线程运行。每个控制器单独向kube-apiserver查询它们跟踪的对象的当前状态。工作节点上每个对象的状态都从本地kubelet发回。
左上角的图形表示运行nginx 1.11的容器。Kubernetes不直接管理容器。相反,kubelet守护进程通过询问容器引擎(可能是Docker或cri-o)的当前状态来检查pod的spec。容器右侧的图形是一个pod,它代表一个检查容器状态的监视循环。kubelet将当前pod规范与容器引擎的响应进行比较,并在必要时终止并重新启动pod。
接下来是一个多容器Pod。虽然使用了几个名称,例如sidecar或ambassador,但这些都属于多容器的Pod。这些名称用于指示在pod中使用第二个容器的特定原因,而不是表示一种新的pod。
在左下角我们看到一个副本集。这个控制器将确保你有一定数量的Pod运行。这些pod都是使用相同的podSpec部署的,这就是为什么它们被称为副本的原因。如果发现pod终止或新的pod产生,replicaSet将创建或终止pod,直到当前运行的pod数符合规范。如果spec要求更少的pod运行,那么任何当前的pod都可能被终止。
右下角的图形说的是deployment。这个控制器允许我们管理部署在Pod中的镜像版本。如果对deployment进行了编辑,将创建一个新的replicaSet,它将使用新的podSpec部署pods。当新的replicaSet中pods可用时,deployment将指示旧的replicaSet关闭pods。一旦旧的pod全部终止,deployment将终止旧的replicaSet并且deployment将返回到只有一个replicaSet正在运行。
3. Deployment清单文件详解
我们利用刚才创建的Deployment来做讲解。想要生成一个新的yaml文件,可以使用
$ kubectl get deployments,rs,pods -o yaml
或者
$ kubectl get deployments,rs,pods -o yaml --dry-run > xxx.file
我们可以看到输出是这样的
apiVersion: v1
items:
- apiVersion: apps/v1
kind: Deployment
- apiVersion
v1表示这个对象的版本是稳定版。在这里,他不是说deployment,而是一个List类型的对象
- items
由于上一行是一个List类型的对象,items就是用来生命这个list中的元素
- - apiVersion
在YAML文件中,横线表示列表的第一个项目,他声明了apiVersion的值是一个叫做apps/v1的对象。他表示这个对象是一个稳定版。Deployment是我们最常用的控制器。
- kind
声明了要创建的对象的类型,这里是deployment
3.1. Metadata
接着上面的输出,后面的这一段是YAML的metadata部分。里面包含了labels,annotations,还有其他的不需要配置的部分。这里显示的并不是所有的配置,还有一些默认配置为false的属性是没有显示出来的,比如podAffinity或者是nodeAffinity
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: 2017-12-21T13:57:07Z
generation: 1
labels:
app: dev-web
name: dev-web
namespace: default
resourceVersion: "774003"
selfLink: /apis/apps/v1/namespaces/default/deployments/dev-web
uid: d52d3a63-e656-11e7-9319-42010a800003
- annotations
他的值不会直接对对象产生作用,但是会提供一些信息,这些信息是给第三方应用来使用的,或者是用来给管理员管理的。和label不一样,他们不可以通过kubectl来选择出来。
- creationTimestamp
表示这个对象的第一次创建时间。即使对象被编辑过,也不会改变。
- generation
表示对象被编辑过多少次,比如我们修改过副本的数量,他就会增加1
- labels
可以是任意的字符串,kubectl和API调用可以通过labels选择或者包含特定的对象。方便管理员在大量的对象当中选出指定的对象
- name
必要的字符串,我们可以从命令行传值。同一个namespace中的名字必须唯一。
- resourceVersion
用来帮助对象并发访问etcd时候,记录先后顺序,每次数据库变化,这个数值就会变化。
- selfLink
用来记录注册在apiserver中的信息
- uid
这个对象在生命周期中的唯一标识
3.2. Spec
deployment的spec有两个,第一个是为ReplicaSet提供配置的,第二个是给Pod提供配置的。
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: dev-web
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
- spec
表示拥有下面的配置的对象,将会被创建
- progressDeadlineSeconds
在对象发生更改之后,如果发生问题,多少秒之后会报告。发生问题的原因可能是限额,镜像问题,或者达到了资源上限
- replicas
表示在ReplicaSet中创建的对象的时候,应该有多少个Pod被创建。如果我们使用kubectl edit命令去修改,比如:原来是1,修改为2,那么就会创建一个新的Pod
- revisionHistoryLimit
在回滚的时候,最多可以回滚到之前多少个版本。
- selector
一系列数据的集合,所有的副本都必须满足selector的条件。不要创建使用同样配置的Pods,这样可能会使得deployment控制器尝试去控制这些资源,导致问题。
- matchLabels
Selector的最基本条件。和matchExpression一起用,表示资源应该往哪个方向去调度。
- strategy
表示在升级的时候应该使用的策略,和后面的type一起使用。也可以配置成recreate,表示在创建新pod之前删除所有现有的Pod。使用RollingUpdate选项,我们就可以控制每次删除Pod的数量。
- maxSurge
每次最多创建Pod的数量,可以是一个百分比,默认是25%,也可以是一个具体的数字。在删除旧的Pods之前,要创建特定数量的新Pod,这样就能保证业务的不间断。
- maxUnavailable
在升级的过程中,最多有多少个不处于Ready状态的Pod
- type
表示在什么过程中,会使用上面的配置,比如:RollingUpdate
3.3. Pod的Spec
下面是Pod的Spec,其实我们应该已经很熟悉了
template:
metadata:
creationTimestamp: null
labels:
app: dev-web
spec:
containers:
- image: nginx:1.13.7-alpine
imagePullPolicy: IfNotPresent
name: dev-web
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
- template
告诉控制器如何去部署一个应用,这里说的是容器
- containers
下面的项目都是用来定义这个容器的关键字
- image
传递给容器引擎的容器名称,引擎会拉取镜像并且创建Pod
- imagePullPolicy
传递给容器引擎的策略配置,用来定义什么时候,或者是否应该下载镜像,还是使用本地的缓存
- name
Pod名称的开头的名字,后面的名字系统会给一个唯一的字符串。
- resources
默认为空。这个是用来是指资源限制的,比如容器CPU限制和内存限制
- terminationMessagePath
可以自定义容器在成功或者失败的时候的输出信息传递的位置
- terminationMessagePolicy
默认的值是File,也可以设置成FallbackToLogsOnError,当容器发生错误的时候,会使用容器日志的最后一段错误日志
- dnsPolicy
表示DNS查询是否要去找coredns,如果配成Default,就会使用所在节点的DNS解析。如果本地解析是文件解析,就使用本地文件,如果是dns解析,就去找dns
- restartPolicy
容器应该重启还是被干掉。自动重启是kuberentes的典型策略。但是自动重启不是没有限制的,每次重启的间隔会变长,最长是5分钟
- scheduleName
使用自定义的调度,而不是kubernetes默认的
- securityContext
根据需要传递一些安全的策略,比如SELinux安全上下文,AppArmor的值,用户或者UID,限制特定的用户才能使用这个容器
- terminationGracePeriodSeconds
在向容器发起SIGTERM(停止)的信号之后,如果没有反应,在多少秒之后发起SIGKILL(杀掉)的信号
3.4. Deployment的状态
status是由系统维护的,我们不能更改,只能查看
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2017-12-21T13:57:07Z
lastUpdateTime: 2017-12-21T13:57:07Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
observedGeneration: 2
readyReplicas: 2
replicas: 2
updatedReplicas: 2
上面的输出显示了如果副本的数量增加到两个,相同的deployment将是什么样子。时间与第一次生成deployment时不同。
- availableReplicas
显示ReplicaSet配置了多少,这个是和上一次readyReplicas的值来进行比较的,用来衡量所有的副本都成功的创建了。
- observedGeneration
表示deployment被更新的频率(次数)。这个信息用来表示deploymeng升级和回滚的状态
4. 扩展和滚动更新(考试重点)
4.1. 扩展
API server允许动态更新大部分的配置,其他是一些不可变的值,这些会根据部署的Kubernetes版本的不同,这些值可能会有所不同。
常见的更新是更新正在运行的副本数。如果将此数字设置为零,则不会有容器,但仍会有副本集和deployment。这是删除deployment的时候,在后端运行的进程。
$ kubectl scale deploy/dev-web --replicas=4
deployment "dev-web" scaled
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
dev-web 4/4 4 4 20s
对于那些非不可变的值,我们也可以通过文编编辑器来修改。
$ kubectl edit deployment nginx
4.2. 滚动更新
同样,我们可以修改已经部署的nginx web服务器的版本到一个老一点的版本。
$ kubectl edit deployment nginx
....
containers:
- image: nginx:1.8 #<<---Set to an older version
imagePullPolicy: IfNotPresent
name: dev-web
....
这样就会触发一个deployment的滚动更新。
我们也可以使用命令来做,创建一个deployment,在创建的时候,记得使用–record命令,我们下面的回滚操作会用到他。
$ kubectl create deploy ghost --image=ghost --record
$ kubectl get deployments ghost -o yaml
deployment.kubernetes.io/revision: "1"
kubernetes.io/change-cause: kubectl create deploy ghost --image=ghost --record
为了让我们之前deployment的ReplicaSet保留下来,您还可以通过scaling up和scaling down来回滚到以前的版本。以前保留的配置数是可配置的,并且每个版本的变化也都会被保存下来。我们就使用kubectl create命令的–record选项更深入地研究回滚,我们还可以通过这个命令进行注释。
4.3. 回滚
如果我们的升级失败了,我们还可以回滚到以前的版本。使用kubectl rollout undo
$ kubectl set image deployment/ghost ghost=ghost:09 --all
$ kubectl rollout history deployment/ghost deployments "ghost":
REVISION CHANGE-CAUSE
1 kubectl create deploy ghost --image=ghost --record
2 kubectl set image deployment/ghost ghost=ghost:09 --all
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ghost-2141819201-tcths 0/1 ImagePullBackOff 0 1m
$ kubectl rollout undo deployment/ghost ; kubectl get pods
NAME READY STATUS RESTARTS AGE
ghost-3378155678-eq5i6 1/1 Running 0 7s
如果我们想回滚到指定的版本,就使用--to-revision=2选项
我们还可以停止或者恢复Deployment
$ kubectl rollout pause deployment/ghost
$ kubectl rollout resume deployment/ghost
我们可以使用kubectl rolling-update命令来告诉ReplicationControllers去做滚动升级,但是这个是由客户端来发起的,所以,如果我们关闭了客户端,滚动升级就会停止。
5. DaemonSet(考试重点)
我们要学习的一个新的对象就是DaemonSet。这个控制器是来保证在集群中的每一个节点上都要存在一个单独的pod。每个POD都使用相同的镜像。如果有集群中有新的节点加入,DaemonSet控制器就会根据配置再创建一个新的Pod。同理,一个node被移除的时候,控制器也会删除Pod。
使用DaemonSet是为了保证某个容器一直在运行。在大型的动态的环境当中,我们可以用它在每个节点来记日志,或者暴露新生成的应用的metric,而不用管理员去手动部署应用。
用法:kind: DaemonSet
我们也有办法让DaemonSet不运行在有kube-api,scheduler这样的master节点的办法,就是使用污点
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
这个例子的tolerations选项让我们的pod不会调度到master节点上,我们后面在说调度的时候还会详细再描述